OmniHuman-1: AI Video Generation by Bytedance
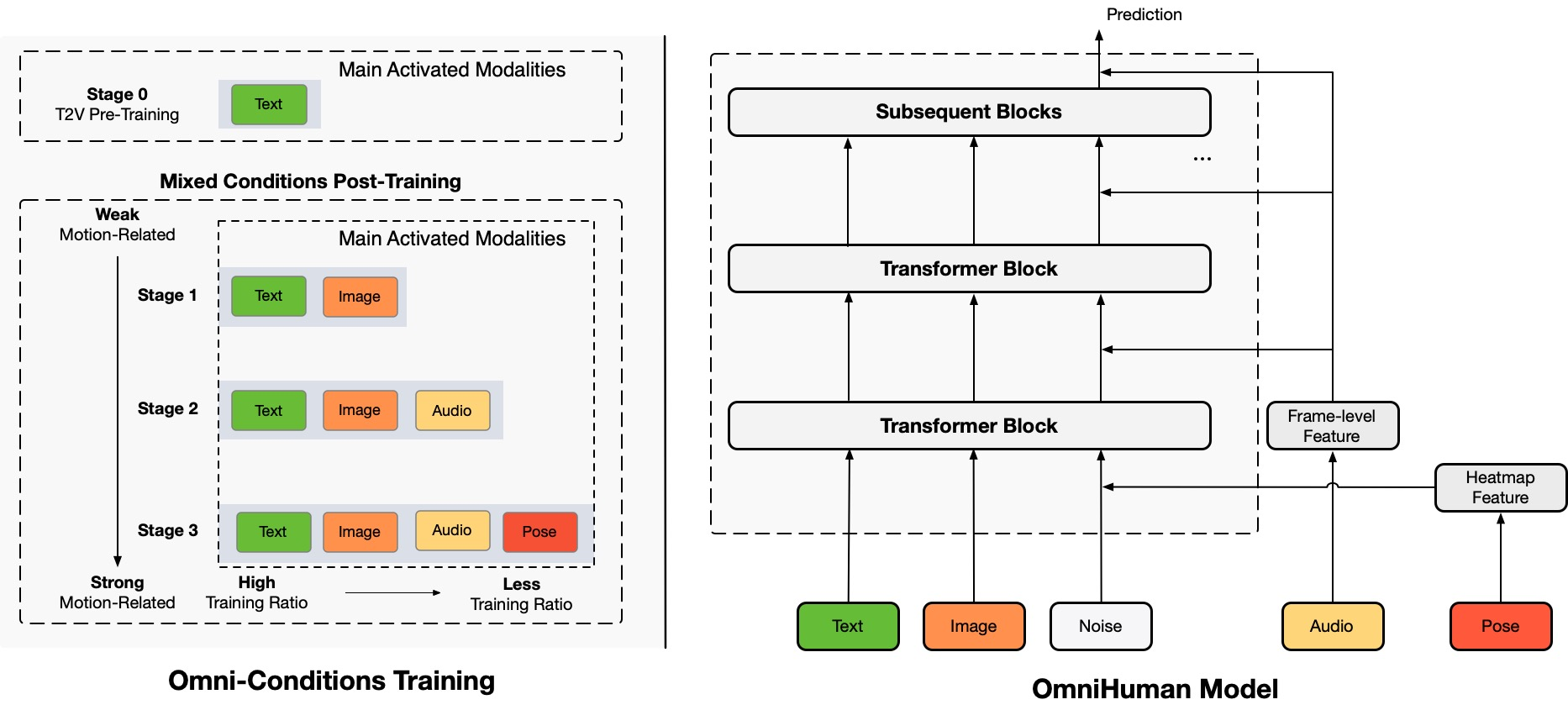
Architecture Overview
TL;DR:我们提出了一种名为 OmniHuman 的端到端多模态人类视频生成框架,它可以基于单一人类图像和运动信号(例如,仅音频、仅视频或音频和视频的组合)生成人类视频。在 OmniHuman 中,我们引入了一种混合条件运动条件训练策略,使模型能够从混合条件数据的可扩展性中受益。这克服了由于高质量数据稀缺而导致的先前端到端方法面临的问题。OmniHuman 显著优于现有方法,基于弱信号输入生成极其逼真的人类视频,特别是音频。它支持任何纵横比的图像输入,无论是肖像、半身还是全身,并在各种场景中提供更逼真和高质量的结果。
生成的视频
OmniHuman 支持各种视觉和音频风格。它可以生成任何纵横比和体型比例(肖像、半身、全身,全部合一)的逼真人类视频,真实感来自于运动、照明和纹理细节等全面方面。
* 请注意,为了生成此页面中的所有结果,只需一张图像和音频,除了视频驱动和组合的演示。为了保持页面整洁,我们省略了参考图像的显示,这些图像通常是生成视频的第一个帧。如果您需要比较或更多信息,请随时联系我们。
唱歌
OmniHuman 可以支持各种音乐风格,并适应多种体态和唱歌形式。它可以处理高音歌曲,并展示不同音乐类型的运动风格。请记住选择最高的视频质量。生成的视频质量也在很大程度上取决于参考图像的质量。
说话
OmniHuman 可以支持任何纵横比的语音输入。它显著改善了手势处理,这对现有方法来说是一个挑战,并生成极其逼真的结果。一些测试案例的音频和图像来自 link1、link2、link3、link4。
多样性
在输入多样性方面,OmniHuman 支持卡通、人工物体、动物和具有挑战性姿势,确保运动特性与每种风格的独特特征相匹配。
更多肖像案例
这里,我们还包括一个专门针对从 CelebV-HQ 数据集中的测试样本派生的肖像纵横比结果的部分。
更多半身案例
这里,我们还提供了更多专门展示手势运动的示例。一些输入图像和音频来自 TED、Pexels 和 AIGC。
与视频驱动的兼容性
由于 OmniHuman 的混合条件训练特性,它不仅可以支持音频驱动,还可以支持视频驱动以模仿特定的视频动作,以及音频和视频驱动的组合(来自 link 的案例)以控制特定的身体部位,如最近的方法。下面我们展示了这些功能。
伦理问题
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us ([email protected]) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
如果您发现这个项目对您的研究有用,您可以引用我们,并查看我们的其他相关工作:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}