OmniHuman-1
什么是 OmniHuman-1?
OmniHuman 是由 ByteDance 研究人员开发的一款创新的端到端 AI 框架,通过单一图像和运动信号(如音频或视频输入)生成超逼真的视频。它可以处理肖像、半身照片或全身图像,提供逼真的运动、自然的手势和卓越的细节。在其核心,OmniHuman 是一个多模态条件模型,完美地集成了各种输入,如静态图像和音频剪辑,以生成高度逼真的视频内容。这一突破通过从最少的数据中合成自然的人类运动,为 AI 生成的视觉效果设定了新的标准,并对娱乐、媒体和虚拟现实等行业产生了深远的影响。
OmniHuman-1 概述
| 特征 | 描述 |
| AI 工具 | OmniHuman-1 |
| 类别 | 多模态 AI 框架 |
| 功能 | 人类视频生成 |
| 生成速度 | 实时视频生成 |
| 研究论文 | arxiv.org/abs/2502.01061 |
| 官方网站 | omnihuman-lab.github.io |
OmniHuman-1 指南
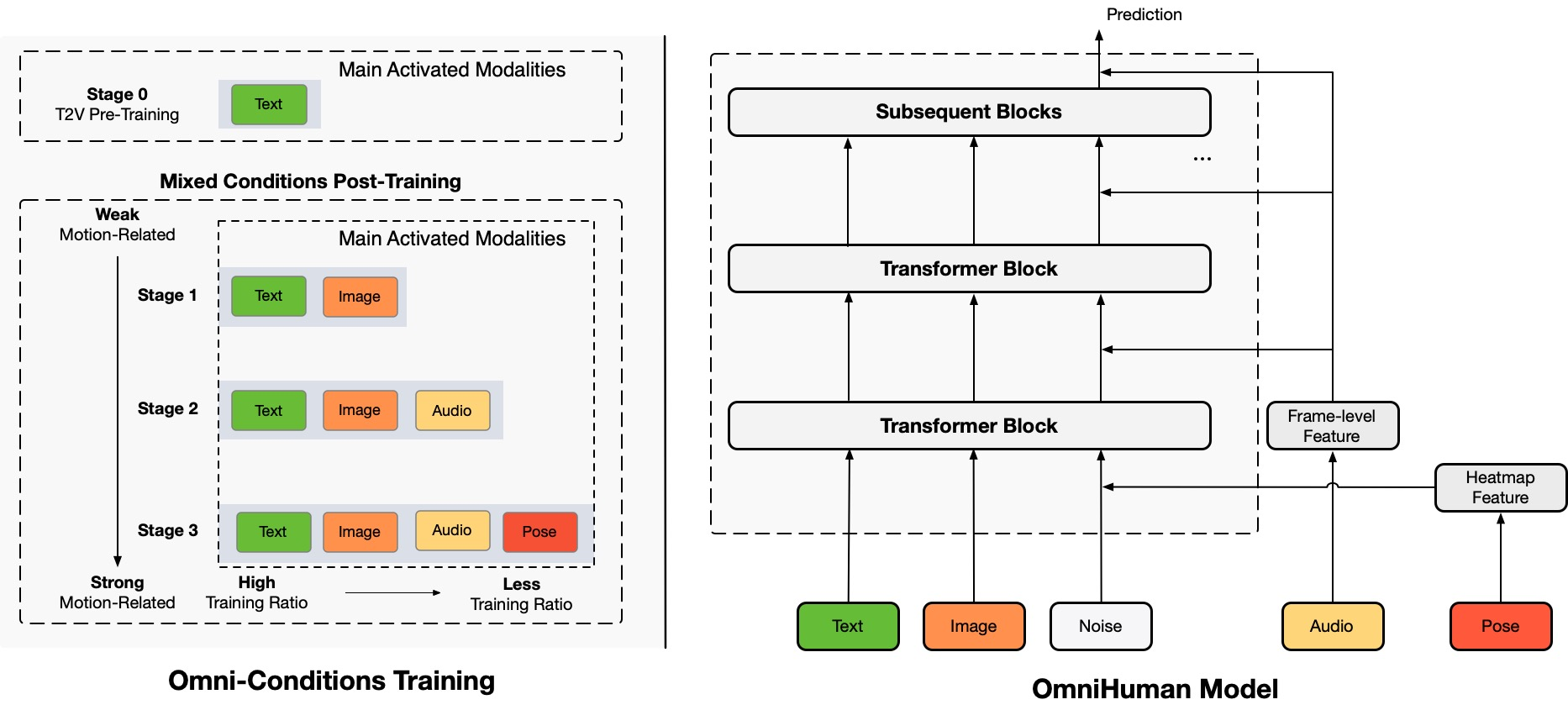
OmniHuman 是一种新的端到端多模态人类视频生成框架,可以通过单一人类图像和各种运动信号(仅音频、仅视频或两者的组合)生成人类视频。OmniHuman 引入了一种混合条件运动条件训练策略,使模型能够从混合条件数据的可扩展性中受益。这种方法有效地解决了由于高质量数据稀缺而导致的先前端到端方法面临的挑战。
OmniHuman 显著优于现有方法,特别是在基于弱信号输入生成极其逼真的人类视频方面,例如音频。
OmniHuman-1 的关键属性
单图像到视频生成
OmniHuman 可以通过单一输入图像生成极其逼真的人类视频,消除了对复杂数据集或多帧的需求。
多模态输入支持
该框架完美地集成了多种输入类型,如图像和音频剪辑,以生成同步和逼真的视频内容。
多样化图像兼容性
无论是肖像、半身照片还是全身图像,OmniHuman 都能以一致的精度和真实感处理所有类型的图像。
自然运动合成
该模型生成流畅、逼真的运动和手势,捕捉到细微的细节,增强了生成视频的真实性。
高度关注细节
该框架在表现复杂细节方面表现出色,如面部表情、肢体语言和环境互动,使视频令人惊叹地逼真。
可扩展的应用
OmniHuman 技术可以适应各种行业,包括娱乐、虚拟现实、游戏和媒体制作,提供广泛的应用潜力。
AI 驱动的创新
通过利用先进的 AI 算法,OmniHuman 代表了人类视频合成领域的重大飞跃,设定了真实性和性能的新标准。
OmniHuman-1 在实践中的应用
唱歌
OmniHuman 让音乐栩栩如生,无论是歌剧还是流行音乐。该模型捕捉到音乐的微妙之处,并将其转化为自然的身体运动和面部表情。例如:
• 手势与歌曲的节奏和风格相一致。
• 面部表情反映了音乐的情感。
说话
OmniHuman 在生成具有精确唇同步和自然手势的逼真说话头像方面表现出色。应用包括:
• 虚拟影响者。
• 教育内容。
卡通和动画
OmniHuman 不仅限于人类;它可以动画化:
• 卡通。
• 动物。
肖像和半身图像
OmniHuman 在特写镜头中也提供逼真的结果。无论是微笑还是戏剧性手势,模型都能捕捉到每一个细节,令人惊叹的真实。
视频输入
OmniHuman 可以模仿参考视频中的动作。例如:
• 使用舞蹈视频作为运动信号,生成另一个人表演相同舞蹈的视频。
• 结合音频和视频信号,动画一个说话头像,模仿说话和手势。
OmniHuman-1 的优缺点
优点
- •高真实感
- •支持多模态输入
- •广泛的应用
- •灵活的视频生成
- •强大的数据扩展性
- •有效利用有限数据
缺点
- •有限的可用性
- •高计算资源需求
- •潜在的伦理和技术问题
- •效果限制
- •依赖输入质量
如何利用 OmniHuman-1?
步骤 1:输入
从一个人的单一图像开始,无论是您自己的照片、名人照片,甚至是卡通角色。然后,添加一个运动信号,例如唱歌或说话的音频剪辑。
步骤 2:处理
OmniHuman 使用一种称为多模态运动条件的技术。这使得模型能够解释和转换运动信号为逼真的人类运动。例如:
• 如果音频是一首歌,模型会生成与音乐节奏和风格相匹配的手势和面部表情。
• 如果是说话,OmniHuman 会创建与单词同步的唇部运动和手势。
步骤 3:输出
结果是一个高质量的视频,给人一种图像中的人真的在唱歌、说话或执行运动信号描述的动作的印象。OmniHuman 在生成逼真结果方面表现出色,即使是弱信号输入,如仅音频。
常见问题
OmniHuman-1 与其他人类视频生成模型有何不同?
OmniHuman-1 是一种多模态人类视频生成框架,可以通过单一人类图像和各种运动信号(仅音频、仅视频或两者的组合)生成人类视频。它引入了一种混合条件运动条件训练策略,使模型能够从混合条件数据的可扩展性中受益。这种方法有效地解决了由于高质量数据稀缺而导致的先前端到端方法面临的挑战。
OmniHuman-1 如何处理不同类型的输入图像?
OmniHuman-1 可以处理各种输入图像类型,包括肖像、半身照片和全身图像。它以一致的精度和真实感处理所有类型的图像。
OmniHuman-1 有哪些局限性?
尽管 OmniHuman-1 在生成逼真的人类视频方面表现出色,但它也有一些局限性。例如,它可能在处理复杂场景或高度详细的环境时遇到困难。此外,该模型需要高质量的参考图像才能生成逼真的结果。最后,OmniHuman-1 是一个大规模模型,需要大量的计算资源。
如何在我的项目中使用 OmniHuman-1?
OmniHuman-1 是为各种应用设计的,包括娱乐、媒体和虚拟现实。您可以使用它为电影、电视节目、游戏等创建逼真的人类视频。要开始,只需上传您的输入图像和运动信号,然后让 OmniHuman-1 完成其余工作。
使用 OmniHuman-1 时有哪些伦理考虑?
尽管 OmniHuman-1 是一个强大的工具,可以生成逼真的人类视频,但在使用 AI 生成的内容时,考虑伦理问题非常重要。确保 OmniHuman-1 生成的内容是合适和尊重的,并考虑 AI 生成视频对社会和个人的潜在影响。