OmniHuman-1: Generación de Videos por IA de Bytedance
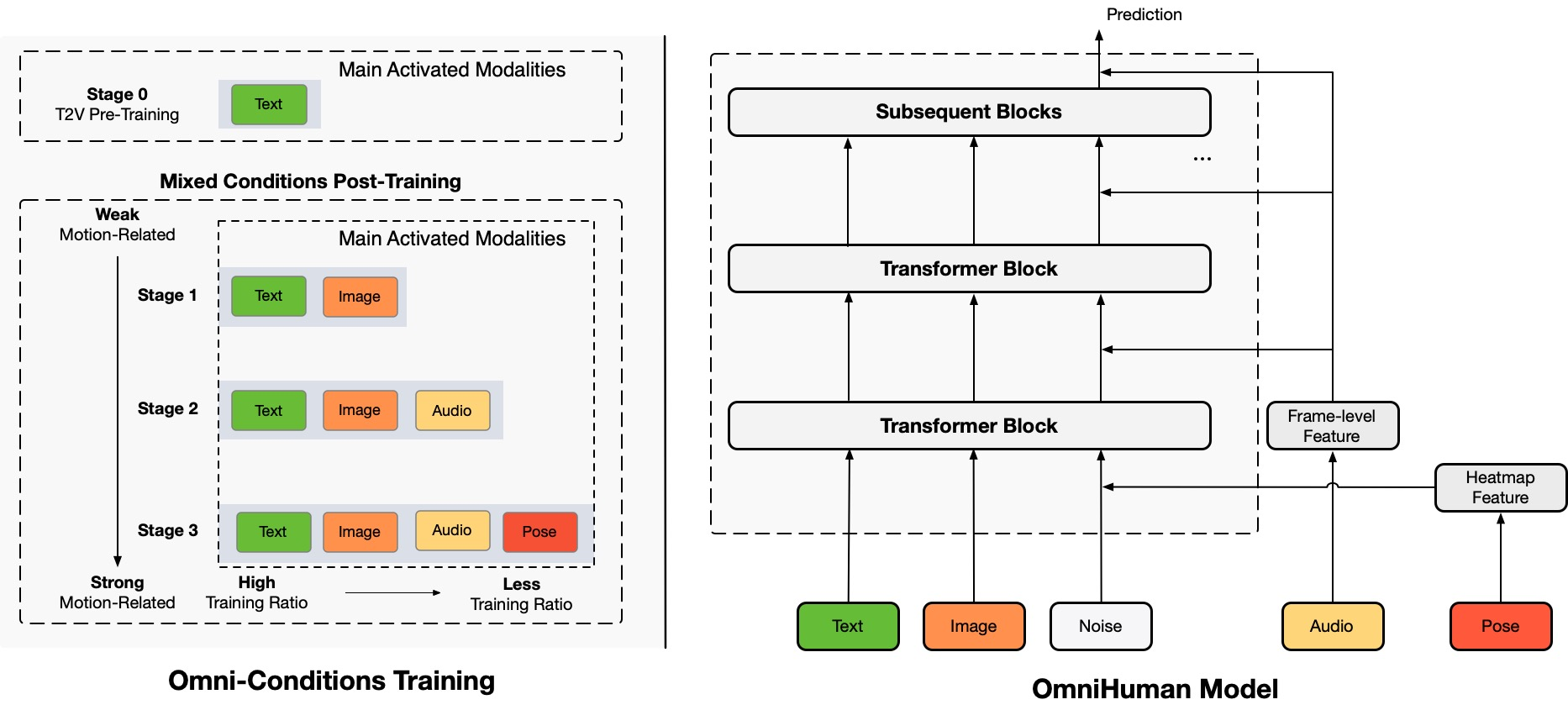
Architecture Overview
TL;DR:Proponemos un marco de generación de videos de personas de extremo a extremo condicionado por multimodalidad llamado OmniHuman, que puede generar videos de personas basados en una sola imagen de una persona y señales de movimiento (por ejemplo, solo audio, solo video o una combinación de audio y video). En OmniHuman, introducimos una estrategia de entrenamiento mixto de condicionamiento de movimiento multimodal, permitiendo que el modelo se beneficie de la escalabilidad de los datos de condicionamiento mixto. Esto supera el problema que enfrentaban los enfoques de extremo a extremo anteriores debido a la escasez de datos de alta calidad. OmniHuman supera significativamente a los métodos existentes, generando videos de personas extremadamente realistas basados en entradas de señales débiles, especialmente audio. Soporta entradas de imagen en cualquier relación de aspecto, ya sean retratos, imágenes de medio cuerpo o de cuerpo completo, y ofrece resultados más realistas y de alta calidad en diversos escenarios.
Videos Generados
OmniHuman soporta diversos estilos visuales y auditivos. Puede generar videos realistas de personas en cualquier relación de aspecto y proporción corporal (retrato, medio cuerpo, cuerpo completo, todo en uno), con un realismo que proviene de aspectos integrales como movimiento, iluminación y detalles de textura.
* Tenga en cuenta que para generar todos los resultados en esta página, solo se requiere una sola imagen y audio, excepto para la demostración de señales de conducción de video y combinadas. Por el bien de un diseño limpio, hemos omitido la visualización de imágenes de referencia, que son el primer fotograma del video generado en la mayoría de los casos. Si necesita comparaciones o más información, no dude en contactarnos.
Cantar
OmniHuman puede soportar diversos estilos de música y múltiples poses corporales y formas de canto. Puede manejar canciones de tono alto y mostrar diferentes estilos de movimiento para diferentes tipos de música. Recuerde seleccionar la mejor calidad de video. La calidad del video generado también depende en gran medida de la calidad de la imagen de referencia.
Hablar
OmniHuman puede soportar entradas en cualquier relación de aspecto en términos de habla. Mejora significativamente el manejo de gestos, que es un desafío para los métodos existentes, y produce resultados extremadamente realistas. El audio y las imágenes para algunos de los casos de prueba provienen de link1, link2, link3, link4.
Diversidad
En términos de diversidad de entrada, OmniHuman soporta caricaturas, objetos artificiales, animales y poses desafiantes, asegurando que las características de movimiento coincidan con las características únicas de cada estilo.
Más Casos de Retrato
Aquí también incluimos una sección dedicada a los resultados de relación de aspecto de retrato, que se derivan de muestras de prueba en los conjuntos de datos CelebV-HQ.
Más Casos de Medio Cuerpo con Manos
Aquí también proporcionamos ejemplos adicionales que muestran específicamente movimientos de gestos. Algunas imágenes y audios de entrada provienen de TED, Pexels y AIGC.
Compatibilidad con Conducción de Video
Debido a las características de entrenamiento de condicionamiento mixto de OmniHuman, puede soportar no solo la conducción de audio, sino también la conducción de video para imitar acciones de video específicas, así como la conducción combinada de audio y video (caso de link) para controlar partes específicas del cuerpo como métodos recientes. A continuación, demostramos estas capacidades.
Preocupaciones Éticas
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us ([email protected]) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Si encuentra este proyecto útil para su investigación, puede citarnos y consultar nuestros otros trabajos relacionados:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}