OmniHuman-1
¿Qué es OmniHuman-1?
OmniHuman, un innovador marco de IA de extremo a extremo desarrollado por investigadores de ByteDance, revoluciona la síntesis de videos de personas al generar videos hiperrealistas a partir de solo una imagen y una señal de movimiento como entrada de audio o video. Capaz de procesar retratos, tomas de medio cuerpo o imágenes de cuerpo completo, ofrece movimientos realistas, gestos naturales y detalles excepcionales. En su núcleo, OmniHuman es un modelo condicionado por multimodalidad que integra sin problemas diversas entradas, como imágenes estáticas y clips de audio, para crear contenido de video altamente realista. Este avance, que sintetiza el movimiento humano natural a partir de datos mínimos, establece nuevos estándares para los visuales generados por IA y tiene implicaciones de gran alcance para industrias como el entretenimiento, los medios y la realidad virtual.
Descripción General de OmniHuman-1
| Característica | Descripción |
| Herramienta de IA | OmniHuman-1 |
| Categoría | Marco de IA Multimodal |
| Función | Generación de Videos de Personas |
| Velocidad de Generación | Generación de video en tiempo real |
| Artículo de investigación | arxiv.org/abs/2502.01061 |
| Sitio web oficial | omnihuman-lab.github.io |
Guía de OmniHuman-1
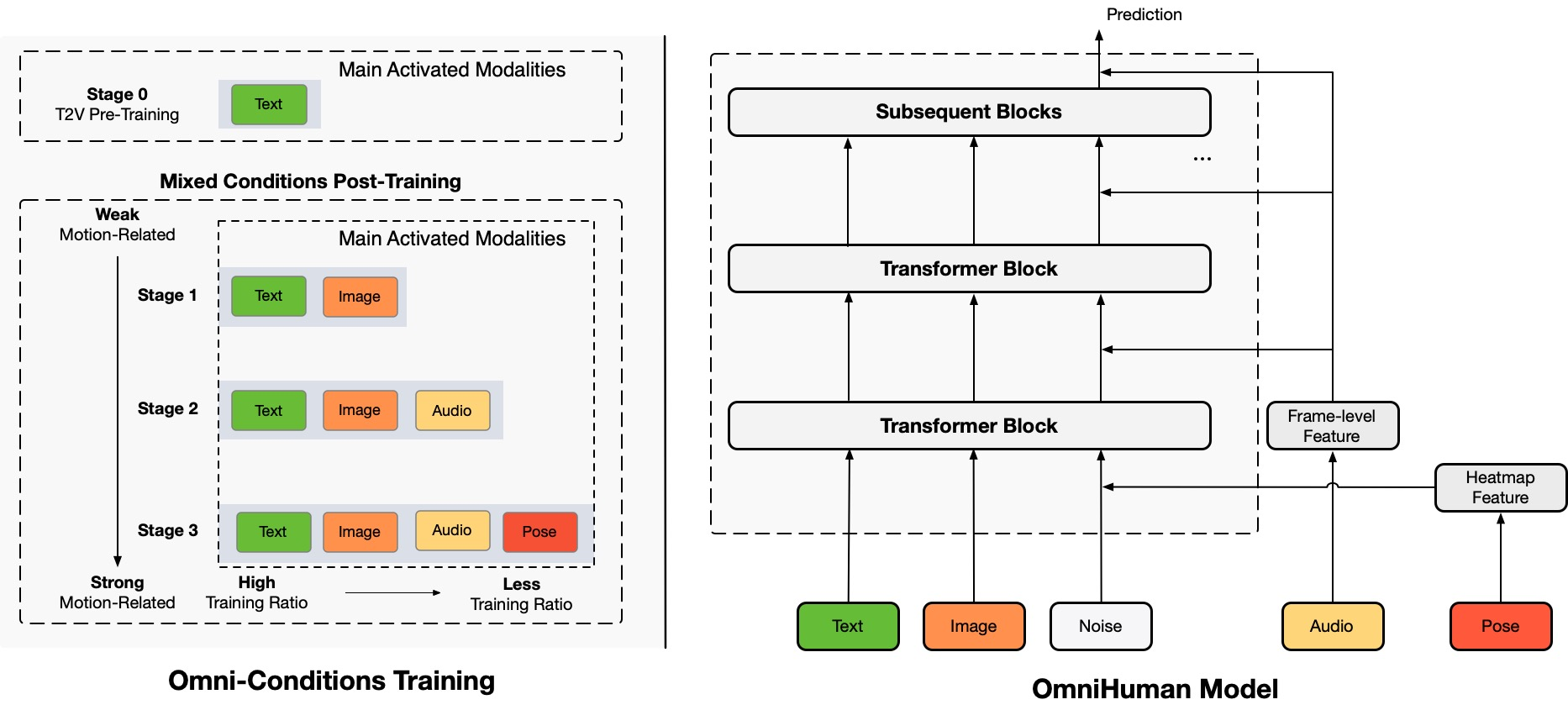
OmniHuman es un nuevo marco de generación de videos de personas de extremo a extremo condicionado por multimodalidad que puede producir videos de personas a partir de una sola imagen de una persona y diversas señales de movimiento, como solo audio, solo video o una combinación de ambos. OmniHuman introduce una estrategia de entrenamiento mixto de condicionamiento de movimiento multimodal, permitiendo que el modelo se beneficie de la escalabilidad de los datos de condicionamiento mixto. Este enfoque aborda eficazmente los desafíos que enfrentaban los métodos de extremo a extremo anteriores debido a la disponibilidad limitada de datos de alta calidad.
OmniHuman supera significativamente a los métodos existentes, especialmente en la generación de videos de personas extremadamente realistas a partir de entradas de señales débiles, como el audio.
Atributos Clave de OmniHuman-1
Generación de Video a partir de una Única Imagen
OmniHuman puede crear videos de personas extremadamente realistas utilizando solo una única imagen de entrada, eliminando la necesidad de conjuntos de datos complejos o múltiples fotogramas.
Soporte de Entrada Multimodal
El marco integra sin problemas múltiples tipos de entrada, como imágenes y clips de audio, para generar contenido de video sincronizado y realista.
Compatibilidad Versátil de Imágenes
Ya sea un retrato, una toma de medio cuerpo o una imagen de cuerpo completo, OmniHuman procesa todos los tipos de imágenes con una precisión y realismo consistentes.
Síntesis de Movimiento Natural
El modelo produce movimientos y gestos fluidos y realistas, capturando detalles sutiles que mejoran la autenticidad de los videos generados.
Alta Atención a los Detalles
El marco se destaca en la representación de detalles intrincados, como expresiones faciales, lenguaje corporal e interacciones ambientales, lo que hace que los videos sean sorprendentemente realistas.
Aplicaciones Escalables
La tecnología de OmniHuman es adaptable a diversas industrias, incluidas el entretenimiento, la realidad virtual, los videojuegos y la producción de medios, ofreciendo un amplio potencial de casos de uso.
Innovación Impulsada por IA
Al aprovechar algoritmos avanzados de IA, OmniHuman representa un salto significativo en la síntesis de videos de personas, estableciendo nuevos estándares de realismo y rendimiento.
Aplicaciones de OmniHuman-1 en la Práctica
Cantar
OmniHuman da vida a la música, ya sea ópera o pop. El modelo captura las sutilezas de la música y las traduce en movimientos corporales y expresiones faciales naturales. Por ejemplo:
• Los gestos se alinean con el ritmo y el estilo de la canción.
• Las expresiones faciales reflejan el estado de ánimo de la música.
Hablar
OmniHuman se destaca en la generación de avatares parlantes realistas con sincronización labial precisa y gestos naturales. Las aplicaciones incluyen:
• Influencers virtuales.
• Contenido educativo.
Caricaturas y Anime
OmniHuman no se limita solo a personas; puede animar:
• Caricaturas.
• Animales.
Imágenes de Retrato y Medio Cuerpo
OmniHuman ofrece resultados realistas incluso en escenarios de primer plano. Ya sea una sonrisa sutil o un gesto dramático, el modelo captura cada detalle con un realismo impresionante.
Entradas de Video
OmniHuman puede imitar acciones de videos de referencia. Por ejemplo:
• Use un video de baile como señal de movimiento para generar un video de otra persona realizando el mismo baile.
• Combine señales de audio y video para animar un avatar parlante que imite tanto el habla como los gestos.
Pros y Contras de OmniHuman-1
Pros
- •Alto realismo
- •Soporte para entradas multimodales
- •Amplia aplicabilidad
- •Generación de video flexible
- •Fuerte escalabilidad de datos
- •Uso eficiente de datos limitados
Contras
- •Disponibilidad limitada
- •Alta demanda de recursos computacionales
- •Posibles problemas éticos y técnicos
- •Limitaciones en el efecto
- •Dependencia de la calidad de la entrada
¿Cómo Aprovechar OmniHuman-1?
Paso 1: Entrada
Comience con una única imagen de una persona, ya sea una foto suya, de una celebridad o incluso de un personaje de caricatura. Luego, agregue una señal de movimiento, como un clip de audio de canto o habla.
Paso 2: Procesamiento
OmniHuman utiliza una técnica llamada condicionamiento de movimiento multimodal. Esto permite que el modelo interprete y traduzca señales de movimiento en movimientos humanos realistas. Por ejemplo:
• Si el audio es una canción, el modelo genera gestos y expresiones faciales que coinciden con el ritmo y el estilo de la música.
• Si es habla, OmniHuman crea movimientos labiales y gestos sincronizados con las palabras.
Paso 3: Salida
El resultado es un video de alta calidad que da la impresión de que la persona en la imagen realmente está cantando, hablando o realizando las acciones descritas por la señal de movimiento. OmniHuman produce resultados realistas incluso con señales débiles como solo entradas de audio.
Preguntas Frecuentes
¿Cuál es la diferencia entre OmniHuman-1 y otros modelos de generación de videos de personas?
OmniHuman-1 es un marco de generación de videos de personas multimodal que puede generar videos de personas a partir de una sola imagen de una persona y diversas señales de movimiento, como solo audio, solo video o una combinación de ambos. Introduce una estrategia de entrenamiento mixto de condicionamiento de movimiento multimodal, permitiendo que el modelo se beneficie de la escalabilidad de los datos de condicionamiento mixto. Este enfoque aborda eficazmente los desafíos que enfrentaban los métodos de extremo a extremo anteriores debido a la disponibilidad limitada de datos de alta calidad.
¿Cómo maneja OmniHuman-1 diferentes tipos de imágenes de entrada?
OmniHuman-1 puede manejar diversos tipos de imágenes de entrada, incluidos retratos, tomas de medio cuerpo e imágenes de cuerpo completo. Procesa todos los tipos de imágenes con una precisión y realismo consistentes.
¿Cuáles son las limitaciones de OmniHuman-1?
Aunque OmniHuman-1 se destaca en la generación de videos de personas realistas, tiene algunas limitaciones. Por ejemplo, puede tener dificultades con escenas complejas o entornos muy detallados. Además, el modelo requiere una imagen de referencia de alta calidad para producir resultados realistas. Finalmente, OmniHuman-1 es un modelo a gran escala que requiere recursos computacionales significativos.
¿Cómo puedo usar OmniHuman-1 en mis proyectos?
OmniHuman-1 está diseñado para ser una herramienta versátil para diversas aplicaciones, incluidas el entretenimiento, los medios y la realidad virtual. Puede usarlo para crear videos de personas realistas para películas, programas de televisión, juegos y más. Para comenzar, simplemente cargue su imagen de entrada y señal de movimiento, y deje que OmniHuman-1 haga el resto.
¿Cuáles son las consideraciones éticas al usar OmniHuman-1?
Aunque OmniHuman-1 es una herramienta poderosa para crear videos de personas realistas, es importante considerar las implicaciones éticas del contenido generado por IA. Es crucial asegurarse de que el contenido generado por OmniHuman-1 sea apropiado y respetuoso, y considerar el impacto potencial de los videos generados por IA en la sociedad y los individuos.