OmniHuman-1
Что такое OmniHuman-1?
OmniHuman — это инновационная энд-ту-энд ИИ-платформа, разработанная исследователями ByteDance, которая революционизирует синтез человеческих видео, генерируя гиперреалистичные видео из одного изображения и сигнала движения, такого как аудио или видеовход. Способный обрабатывать портреты, полутела или изображения полного тела, он обеспечивает реалистичные движения, естественные жесты и исключительные детали. В основе OmniHuman лежит многомодальная условная модель, которая бесшовно интегрирует различные входы, такие как статические изображения и аудиоклипы, для создания высокореалистичного видеоконтента. Этот прорыв, который синтезирует естественные человеческие движения из минимальных данных, устанавливает новые стандарты для визуальных образов, созданных ИИ, и имеет далеко идущие последствия для таких отраслей, как развлечения, СМИ и виртуальная реальность.
Обзор OmniHuman-1
| Характеристика | Описание |
| Инструмент ИИ | OmniHuman-1 |
| Категория | Многомодальная ИИ-платформа |
| Функция | Генерация человеческих видео |
| Скорость генерации | Генерация видео в реальном времени |
| Научная статья | arxiv.org/abs/2502.01061 |
| Официальный сайт | omnihuman-lab.github.io |
Руководство по OmniHuman-1
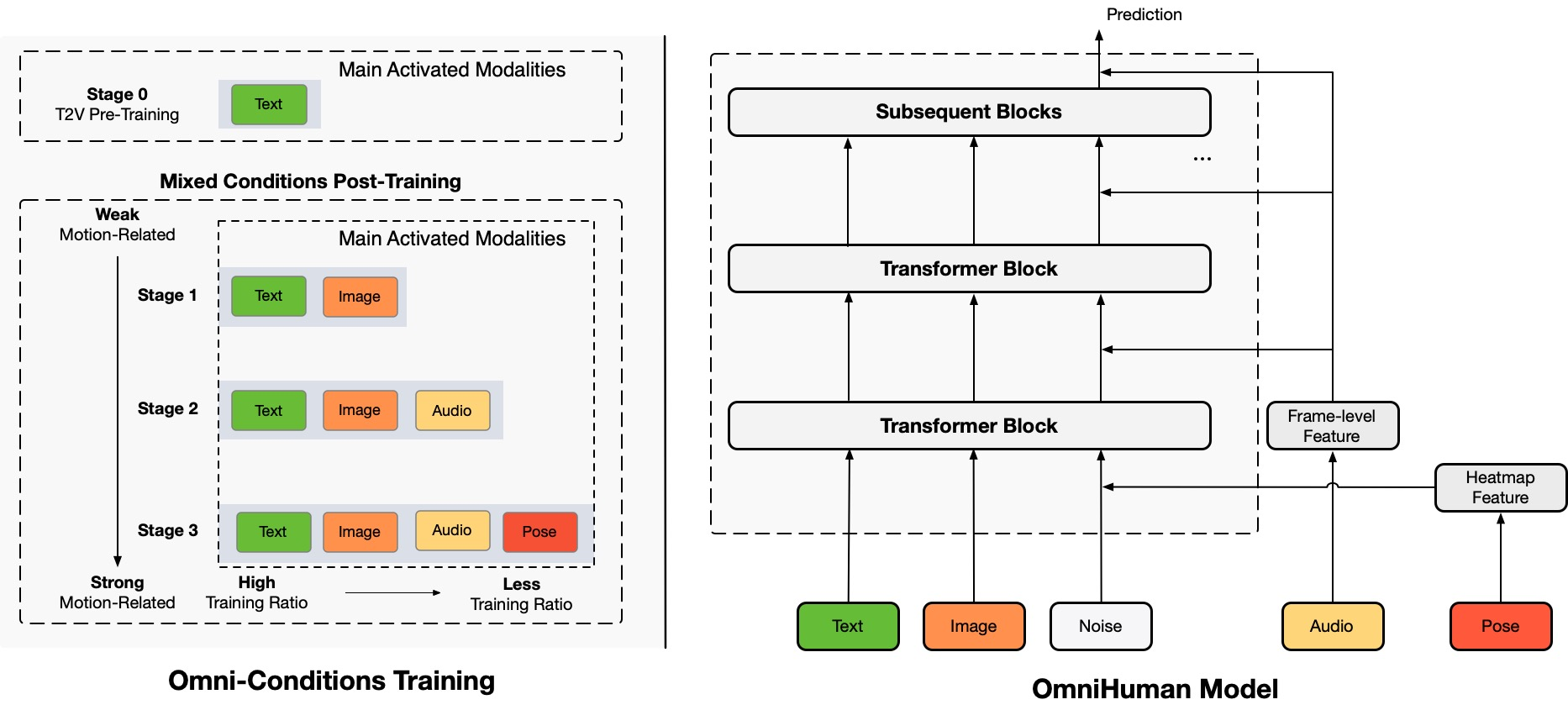
OmniHuman — это новый энд-ту-энд многомодальный фреймворк для генерации человеческих видео, который может создавать человеческие видео из одного человеческого изображения и различных сигналов движения, таких как только аудио, только видео или их комбинация. OmniHuman вводит стратегию смешанного обучения с условием многомодальности движения, что позволяет модели использовать преимущества масштабируемости данных смешанного условия. Это решает проблему, с которой сталкивались предыдущие энд-ту-энд подходы из-за дефицита высококачественных данных.
OmniHuman значительно превосходит существующие методы, особенно в генерации чрезвычайно реалистичных человеческих видео на основе слабых сигнальных входов, таких как аудио.
Ключевые атрибуты OmniHuman-1
Генерация видео из одного изображения
OmniHuman может создавать чрезвычайно реалистичные человеческие видео, используя одно входное изображение, исключая необходимость в сложных наборах данных или множественных кадрах.
Поддержка многомодальных входов
Фреймворк бесшовно интегрирует различные типы входов, такие как изображения и аудиоклипы, для генерации синхронизированного и реалистичного видеоконтента.
Универсальная совместимость изображений
Будь то портрет, полутело или полное тело, OmniHuman обрабатывает все типы изображений с постоянной точностью и реализмом.
Синтез естественных движений
Модель производит плавные и реалистичные движения и жесты, захватывая тонкие детали, которые улучшают аутентичность сгенерированных видео.
Высокое внимание к деталям
Фреймворк превосходно справляется с рендерингом сложных деталей, таких как выражения лица, язык тела и взаимодействие с окружающей средой, делая видео поразительно реалистичными.
Масштабируемые применения
Технология OmniHuman адаптируется к различным отраслям, включая развлечения, виртуальную реальность, игры и производство медиа, предлагая широкий спектр возможных сценариев использования.
Инновации, управляемые ИИ
Используя передовые алгоритмы ИИ, OmniHuman представляет собой значительный прогресс в синтезе человеческих видео, устанавливая новые стандарты реализма и производительности.
Применение OmniHuman-1 на практике
Пение
OmniHuman оживляет музыку, будь то опера или поп. Модель захватывает нюансы музыки и переводит их в естественные движения тела и выражения лица. Например:
• Жесты соответствуют ритму и стилю песни.
• Выражения лица отражают настроение музыки.
Разговор
OmniHuman преуспевает в создании реалистичных говорящих аватаров с точной синхронизацией губ и естественными жестами. Применения включают:
• Виртуальные инфлюенсеры.
• Образовательный контент.
Мультфильмы и аниме
OmniHuman не ограничивается людьми; он может анимировать:
• Мультфильмы.
• Животных.
Изображения портретов и полутела
OmniHuman также обеспечивает реалистичные результаты даже в крупных планах. Будь то легкая улыбка или драматический жест, модель захватывает каждую деталь с поразительным реализмом.
Видеовходы
OmniHuman может имитировать действия из эталонных видео. Например:
• Используйте видео танца в качестве сигнала движения, чтобы сгенерировать видео другого человека, выполняющего тот же танец.
• Комбинируйте аудио и видео сигналы, чтобы анимировать говорящего аватара, который имитирует как речь, так и жесты.
Преимущества и недостатки OmniHuman-1
Преимущества
- •Высокий реализм
- •Поддержка многомодальных входов
- •Широкая применимость
- •Гибкая генерация видео
- •Сильная масштабируемость данных
- •Эффективное использование ограниченных данных
Недостатки
- •Ограниченная доступность
- •Высокая потребность в вычислительных ресурсах
- •Потенциальные этические и технические проблемы
- •Ограничения в эффекте
- •Зависимость от качества входа
Как использовать OmniHuman-1?
Шаг 1: Вход
Начните с одного изображения человека, будь то ваше фото, фото знаменитости или даже мультипликационного персонажа. Затем добавьте сигнал движения, такой как аудиоклип с пением или разговором.
Шаг 2: Обработка
OmniHuman использует технику многомодального условия движения. Это позволяет модели интерпретировать и переводить сигналы движения в реалистичные человеческие движения. Например:
• Если аудио — это песня, модель генерирует жесты и выражения лица, соответствующие ритму и стилю музыки.
• Если это разговор, OmniHuman создает движения губ и жесты, синхронизированные со словами.
Шаг 3: Выход
Результатом является высококачественное видео, которое создает впечатление, что человек на изображении действительно поет, разговаривает или выполняет действия, описанные сигналом движения. OmniHuman преуспевает в создании реалистичных результатов даже со слабыми сигналами, такими как только аудиовход.
Часто задаваемые вопросы
В чем разница между OmniHuman-1 и другими моделями генерации человеческих видео?
OmniHuman-1 — это многомодальный фреймворк для генерации человеческих видео, который может генерировать человеческие видео из одного человеческого изображения и различных сигналов движения, таких как только аудио, только видео или их комбинация. Он вводит стратегию смешанного обучения с условием многомодальности движения, что позволяет модели использовать преимущества масштабируемости данных смешанного условия. Это решает проблему, с которой сталкивались предыдущие энд-ту-энд подходы из-за дефицита высококачественных данных.
Как OmniHuman-1 обрабатывает различные типы входных изображений?
OmniHuman-1 может обрабатывать различные типы входных изображений, такие как портреты, полутела и полные тела. Он обрабатывает все типы изображений с постоянной точностью и реализмом.
Какие ограничения у OmniHuman-1?
Хотя OmniHuman-1 преуспевает в генерации реалистичных человеческих видео, у него есть некоторые ограничения. Например, он может испытывать трудности с сложными сценами или очень детализированными средами. Кроме того, модель требует высококачественного опорного изображения для генерации реалистичных результатов. Наконец, OmniHuman-1 — это масштабная модель, требующая значительных вычислительных ресурсов.
Как я могу использовать OmniHuman-1 в своих проектах?
OmniHuman-1 разработан как универсальный инструмент для различных применений, включая развлечения, СМИ и виртуальную реальность. Вы можете использовать его для создания реалистичных человеческих видео для фильмов, телепередач, игр и многого другого. Чтобы начать, просто загрузите входное изображение и сигнал движения, и позвольте OmniHuman-1 сделать остальное.
Какие этические соображения следует учитывать при использовании OmniHuman-1?
Хотя OmniHuman-1 — это мощный инструмент для создания реалистичных человеческих видео, важно учитывать этические последствия контента, созданного ИИ. Важно убедиться, что контент, созданный OmniHuman-1, является приемлемым и уважительным, и учитывать потенциальное влияние видео, созданных ИИ, на общество и отдельных лиц.