OmniHuman-1
O que é OmniHuman-1?
OmniHuman, uma estrutura inovadora de IA de ponta a ponta desenvolvida por pesquisadores da ByteDance, revoluciona a síntese de vídeos de pessoas ao gerar vídeos hiper-realistas a partir de apenas uma imagem e um sinal de movimento, como entrada de áudio ou vídeo. Capaz de processar retratos, fotos de meio corpo ou imagens de corpo inteiro, oferece movimentos realistas, gestos naturais e detalhes excepcionais. No seu núcleo, o OmniHuman é um modelo condicionado por multimodalidade que integra perfeitamente diversas entradas, como imagens estáticas e clipes de áudio, para criar conteúdo de vídeo altamente realista. Este avanço, que sintetiza o movimento humano natural a partir de dados mínimos, estabelece novos padrões para visuais gerados por IA e tem implicações de longo alcance para indústrias como entretenimento, mídia e realidade virtual.
Visão Geral do OmniHuman-1
| Característica | Descrição |
| Ferramenta de IA | OmniHuman-1 |
| Categoria | Estrutura de IA Multimodal |
| Função | Geração de Vídeos de Pessoas |
| Velocidade de Geração | Geração de vídeo em tempo real |
| Artigo de pesquisa | arxiv.org/abs/2502.01061 |
| Site oficial | omnihuman-lab.github.io |
Guia do OmniHuman-1
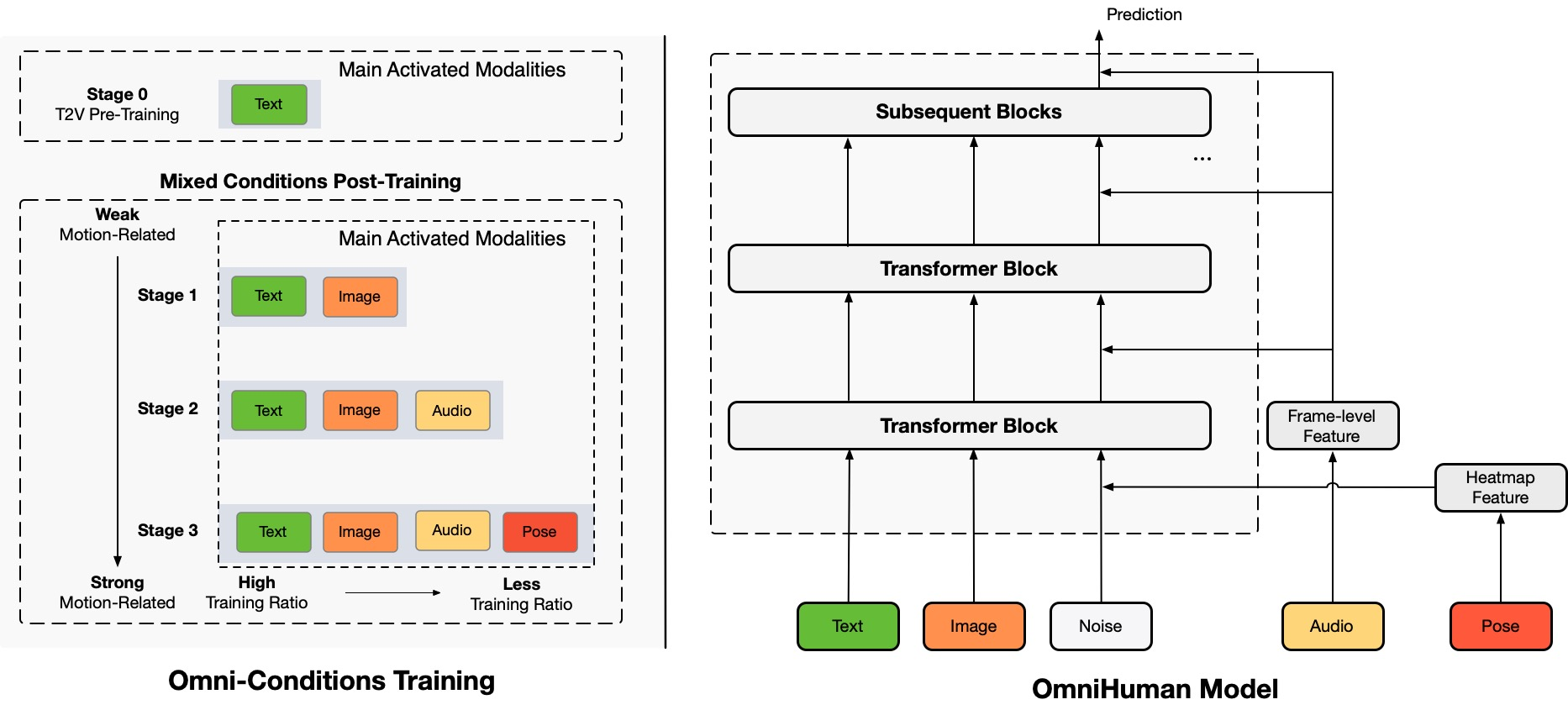
O OmniHuman é uma nova estrutura de geração de vídeos de pessoas de ponta a ponta condicionada por multimodalidade que pode produzir vídeos de pessoas a partir de uma única imagem de uma pessoa e diversos sinais de movimento, como apenas áudio, apenas vídeo ou uma combinação de ambos. O OmniHuman introduz uma estratégia de treinamento misto de condicionamento de movimento multimodal, permitindo que o modelo se beneficie da escalabilidade dos dados de condicionamento misto. Este enfoque aborda eficazmente os desafios enfrentados pelos métodos de ponta a ponta anteriores devido à disponibilidade limitada de dados de alta qualidade.
O OmniHuman supera significativamente os métodos existentes, especialmente na geração de vídeos de pessoas extremamente realistas a partir de entradas de sinais fracos, como áudio.
Atributos Principais do OmniHuman-1
Geração de Vídeo a partir de uma Única Imagem
O OmniHuman pode criar vídeos de pessoas extremamente realistas usando apenas uma única imagem de entrada, eliminando a necessidade de conjuntos de dados complexos ou múltiplos quadros.
Suporte de Entrada Multimodal
A estrutura integra perfeitamente múltiplos tipos de entrada, como imagens e clipes de áudio, para gerar conteúdo de vídeo sincronizado e realista.
Compatibilidade Versátil de Imagens
Seja um retrato, uma foto de meio corpo ou uma imagem de corpo inteiro, o OmniHuman processa todos os tipos de imagens com precisão e realismo consistentes.
Síntese de Movimento Natural
O modelo produz movimentos e gestos fluidos e realistas, capturando detalhes sutis que aprimoram a autenticidade dos vídeos gerados.
Alta Atenção aos Detalhes
A estrutura se destaca na representação de detalhes intrincados, como expressões faciais, linguagem corporal e interações ambientais, tornando os vídeos impressionantemente realistas.
Aplicações Escaláveis
A tecnologia do OmniHuman é adaptável a diversas indústrias, incluindo entretenimento, realidade virtual, jogos e produção de mídia, oferecendo um amplo potencial de casos de uso.
Inovação Impulsionada por IA
Ao aproveitar algoritmos avançados de IA, o OmniHuman representa um salto significativo na síntese de vídeos de pessoas, estabelecendo novos padrões de realismo e desempenho.
Aplicações do OmniHuman-1 na Prática
Cantar
O OmniHuman dá vida à música, seja ópera ou pop. O modelo captura as sutilezas da música e as traduz em movimentos corporais e expressões faciais naturais. Por exemplo:
• Os gestos se alinham com o ritmo e o estilo da música.
• As expressões faciais refletem o estado de espírito da música.
Falar
O OmniHuman se destaca na geração de avatares falantes realistas com sincronização labial precisa e gestos naturais. As aplicações incluem:
• Influenciadores virtuais.
• Conteúdo educacional.
Desenhos Animados e Anime
O OmniHuman não se limita apenas a pessoas; pode animar:
• Desenhos animados.
• Animais.
Imagens de Retrato e Meio Corpo
O OmniHuman oferece resultados realistas mesmo em cenários de close-up. Seja um sorriso sutil ou um gesto dramático, o modelo captura cada detalhe com um realismo impressionante.
Entradas de Vídeo
O OmniHuman pode imitar ações de vídeos de referência. Por exemplo:
• Use um vídeo de dança como sinal de movimento para gerar um vídeo de outra pessoa realizando a mesma dança.
• Combine sinais de áudio e vídeo para animar um avatar falante que imite tanto a fala quanto os gestos.
Prós e Contras do OmniHuman-1
Prós
- •Alto realismo
- •Suporte para entradas multimodais
- •Ampla aplicabilidade
- •Geração de vídeo flexível
- •Forte escalabilidade de dados
- •Uso eficiente de dados limitados
Contras
- •Disponibilidade limitada
- •Alta demanda de recursos computacionais
- •Possíveis problemas éticos e técnicos
- •Limitações no efeito
- •Dependência da qualidade da entrada
Como Aproveitar o OmniHuman-1?
Passo 1: Entrada
Comece com uma única imagem de uma pessoa, seja uma foto sua, de uma celebridade ou até mesmo de um personagem de desenho animado. Em seguida, adicione um sinal de movimento, como um clipe de áudio de canto ou fala.
Passo 2: Processamento
O OmniHuman usa uma técnica chamada condicionamento de movimento multimodal. Isso permite que o modelo interprete e traduza sinais de movimento em movimentos humanos realistas. Por exemplo:
• Se o áudio for uma música, o modelo gera gestos e expressões faciais que combinam com o ritmo e o estilo da música.
• Se for fala, o OmniHuman cria movimentos labiais e gestos sincronizados com as palavras.
Passo 3: Saída
O resultado é um vídeo de alta qualidade que dá a impressão de que a pessoa na imagem realmente está cantando, falando ou realizando as ações descritas pelo sinal de movimento. O OmniHuman produz resultados realistas mesmo com sinais fracos, como apenas entradas de áudio.
Perguntas Frequentes
Qual é a diferença entre OmniHuman-1 e outros modelos de geração de vídeos de pessoas?
O OmniHuman-1 é uma estrutura de geração de vídeos de pessoas multimodal que pode gerar vídeos de pessoas a partir de uma única imagem de uma pessoa e diversos sinais de movimento, como apenas áudio, apenas vídeo ou uma combinação de ambos. Introduz uma estratégia de treinamento misto de condicionamento de movimento multimodal, permitindo que o modelo se beneficie da escalabilidade dos dados de condicionamento misto. Este enfoque aborda eficazmente os desafios enfrentados pelos métodos de ponta a ponta anteriores devido à disponibilidade limitada de dados de alta qualidade.
Como o OmniHuman-1 lida com diferentes tipos de imagens de entrada?
O OmniHuman-1 pode lidar com diversos tipos de imagens de entrada, incluindo retratos, fotos de meio corpo e imagens de corpo inteiro. Processa todos os tipos de imagens com precisão e realismo consistentes.
Quais são as limitações do OmniHuman-1?
Embora o OmniHuman-1 se destaque na geração de vídeos de pessoas realistas, ele tem algumas limitações. Por exemplo, pode ter dificuldades com cenas complexas ou ambientes muito detalhados. Além disso, o modelo requer uma imagem de referência de alta qualidade para produzir resultados realistas. Por fim, o OmniHuman-1 é um modelo em grande escala que requer recursos computacionais significativos.
Como posso usar o OmniHuman-1 em meus projetos?
O OmniHuman-1 é projetado para ser uma ferramenta versátil para diversas aplicações, incluindo entretenimento, mídia e realidade virtual. Você pode usá-lo para criar vídeos de pessoas realistas para filmes, programas de TV, jogos e muito mais. Para começar, basta fazer o upload da sua imagem de entrada e sinal de movimento, e deixar o OmniHuman-1 fazer o resto.
Quais são as considerações éticas ao usar o OmniHuman-1?
Embora o OmniHuman-1 seja uma ferramenta poderosa para criar vídeos de pessoas realistas, é importante considerar as implicações éticas do conteúdo gerado por IA. É crucial garantir que o conteúdo gerado pelo OmniHuman-1 seja apropriado e respeitoso, e considerar o impacto potencial dos vídeos gerados por IA na sociedade e nos indivíduos.