OmniHuman-1
OmniHuman-1とは?
OmniHumanは、ByteDanceの研究者によって開発されたエンドツーエンドの革新的なAIフレームワークで、単一の画像と動きの信号(例えば、オーディオやビデオ入力)からハイパーリアルなビデオを生成します。ポートレート、ハーフボディ、フルボディの画像を処理し、リアルな動き、自然なジェスチャー、例外的な詳細を提供します。OmniHumanの中核にあるのは、多様性条件付きモデルであり、静止画像やオーディオクリップなどの異なる入力をシームレスに統合し、非常にリアルなビデオコンテンツを作成します。この突破は、最小限のデータから自然な人間の動きを合成し、AI生成ビジュアルの新しい基準を設定し、エンターテインメント、メディア、仮想現実などの業界に大きな影響を与えます。
OmniHuman-1の概要
| 特徴 | 説明 |
| AIツール | OmniHuman-1 |
| カテゴリ | 多様性AIフレームワーク |
| 機能 | 人間ビデオ生成 |
| 生成速度 | リアルタイムビデオ生成 |
| 研究論文 | arxiv.org/abs/2502.01061 |
| 公式ウェブサイト | omnihuman-lab.github.io |
OmniHuman-1ガイド
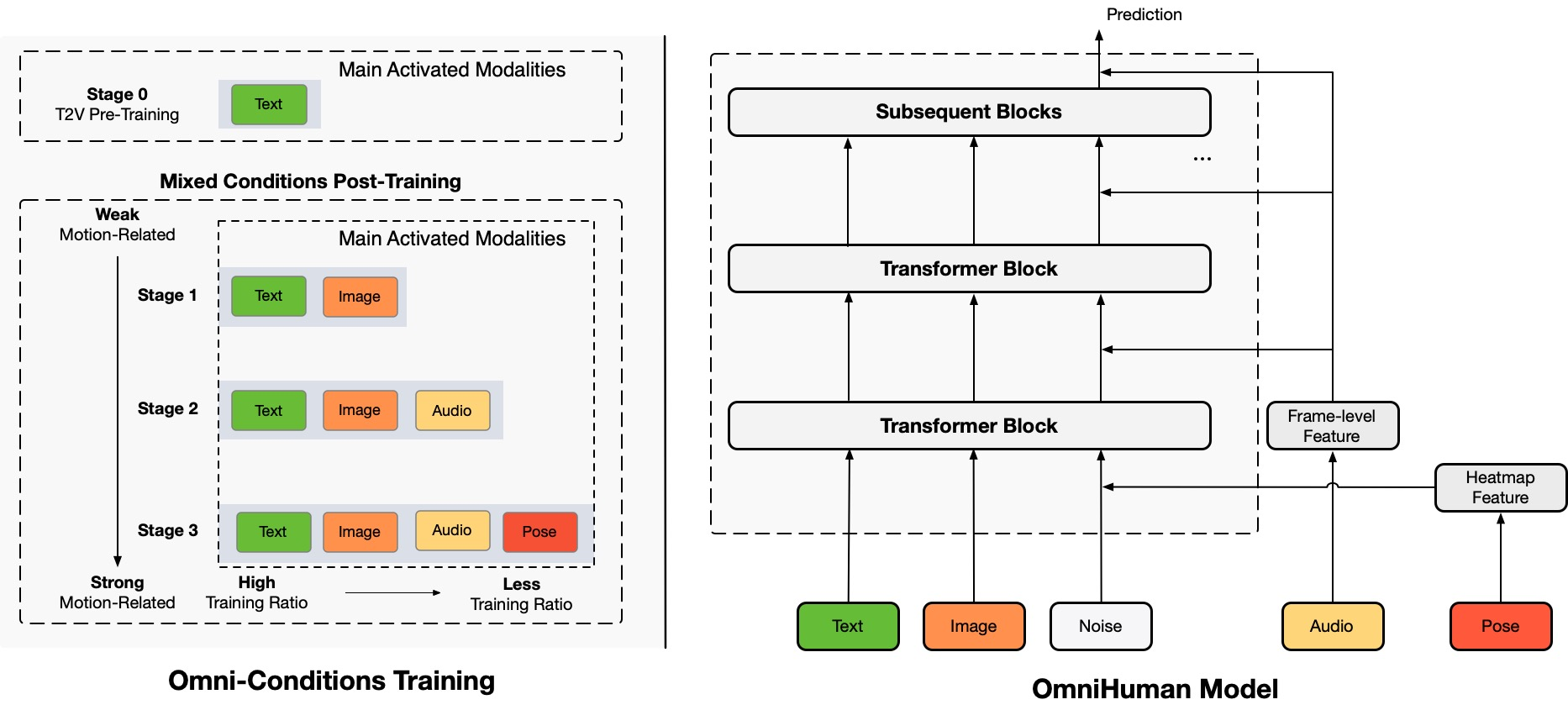
OmniHumanは、単一の人間の画像とさまざまな動きの信号(例えば、オーディオのみ、ビデオのみ、またはその両方)から人間のビデオを生成する新しいエンドツーエンドの多様性条件付き人間ビデオ生成フレームワークです。OmniHumanは、混合条件付き動きの条件付け混合トレーニング戦略を導入しており、これによりモデルは混合条件付けデータのスケーリングの恩恵を受けることができます。これにより、高品質なデータの希少さによる以前のエンドツーエンドアプローチの問題が解決されます。
OmniHumanは、特にオーディオのような弱い信号入力に基づいて、既存の方法を大幅に上回る非常にリアルな人間のビデオを生成します。
OmniHuman-1の特徴
単一画像からのビデオ生成
OmniHumanは、複雑なデータセットや複数のフレームを必要とせずに、単一の入力画像を使用して非常にリアルな人間のビデオを作成することができます。
多様性入力のサポート
フレームワークは、画像やオーディオクリップなどの複数の入力タイプをシームレスに統合し、同期されたリアルなビデオコンテンツを生成します。
柔軟な画像互換性
ポートレート、ハーフボディ、フルボディのどの画像でも、OmniHumanは一貫した精度とリアリズムですべての画像タイプを処理します。
自然な動きの合成
モデルは、生成されたビデオの真正性を向上させる微妙な詳細を捉える、滑らかでリアルな動きとジェスチャーを生成します。
細部への高い注意
フレームワークは、表情、ボディランゲージ、環境相互作用などの複雑な詳細のレンダリングにおいて優れており、ビデオを驚くほどリアルにします。
スケーラブルな応用
OmniHumanの技術は、エンターテインメント、仮想現実、ゲーム、メディア制作などのさまざまな業界に適応でき、広範な使用例の可能性を提供します。
AI主導の革新
高度なAIアルゴリズムを活用し、OmniHumanは人間ビデオ合成において重要な進歩を遂げ、リアリズムとパフォーマンスの新しい基準を設定しています。
OmniHuman-1の実践的応用
歌
OmniHumanは、オペラやポップスなどの音楽に命を吹き込みます。モデルは音楽の微妙なニュアンスを捉え、自然な体の動きと表情に変換します。例えば:
• ジェスチャーは歌のリズムとスタイルに合わせて調整されます。
• 表情は音楽のムードを反映します。
話す
OmniHumanは、正確なリップシンクと自然なジェスチャーを持つリアルな話すアバターを生成するのに優れています。応用例は以下の通りです:
• 仮想インフルエンサー。
• 教育コンテンツ。
カートゥーンとアニメ
OmniHumanは人間に限定されていません。アニメーションすることができます:
• カートゥーン。
• 動物。
ポートレートとハーフボディの画像
OmniHumanは、クローズアップシーンでもリアルな結果を提供します。微妙な笑顔やドラマチックなジェスチャーであっても、モデルは驚くほどのリアリズムですべての詳細を捉えます。
ビデオ入力
OmniHumanは、参照ビデオのアクションを模倣することができます。例えば:
• ダンスビデオを動きの信号として使用して、別の人が同じダンスを行うビデオを生成します。
• オーディオとビデオの信号を組み合わせて、話すアバターをアニメーション化し、話し方とジェスチャーの両方を模倣します。
OmniHuman-1のメリットとデメリット
メリット
- •高いリアリズム
- •多様性入力のサポート
- •広範な適用可能性
- •柔軟なビデオ生成
- •強力なデータスケーリング
- •限られたデータの効率的な使用
デメリット
- •限られた可用性
- •高いコンピューティングリソースの需要
- •潜在的な倫理的および技術的な問題
- •効果における制限
- •入力品質への依存
OmniHuman-1をどのように活用するか?
ステップ1:入力
自分自身、セレブリティ、またはカートゥーンキャラクターの写真を含む単一の画像から始めます。次に、歌や話すオーディオクリップなどの動きの信号を追加します。
ステップ2:処理
OmniHumanは、多様性動きの条件付けと呼ばれる技術を使用しています。これにより、モデルは動きの信号をリアルな人間の動きに解釈して変換することができます。例えば:
• オーディオが歌の場合、モデルは音楽のリズムとスタイルに合わせたジェスチャーと表情を生成します。
• 話す場合、OmniHumanは言葉に同期した口の動きとジェスチャーを作成します。
ステップ3:出力
結果は、画像の人物が実際に歌ったり、話したり、動きの信号で説明されたアクションを実行しているかのような高品質なビデオです。OmniHumanは、オーディオ入力のみでもリアルな結果を生成するのに優れています。
よくある質問
OmniHuman-1と他の人間ビデオ生成モデルとの違いは何ですか?
OmniHuman-1は、単一の人間の画像とさまざまな動きの信号(例えば、オーディオのみ、ビデオのみ、またはその両方)から人間のビデオを生成する多様性条件付き人間ビデオ生成フレームワークです。混合条件付き動きの条件付け混合トレーニング戦略を導入しており、これによりモデルは混合条件付けデータのスケーリングの恩恵を受けることができます。これにより、高品質なデータの希少さによる以前のエンドツーエンドアプローチの問題が解決されます。
OmniHuman-1はどのようにして異なる入力画像のタイプを処理しますか?
OmniHuman-1は、ポートレート、ハーフボディ、フルボディの画像など、さまざまな入力画像のタイプを処理することができます。どのタイプの画像でも、一貫した精度とリアリズムで処理します。
OmniHuman-1の制限は何ですか?
OmniHuman-1はリアルな人間ビデオを生成するのに優れていますが、いくつかの制限があります。例えば、複雑なシーンや非常に詳細な環境では苦労することがあります。また、モデルはリアルな結果を生成するために高品質な参照画像を必要とします。最後に、OmniHuman-1は大規模なモデルであり、大量のコンピューティングリソースを必要とします。
OmniHuman-1をプロジェクトでどのように使用できますか?
OmniHuman-1は、エンターテインメント、メディア、仮想現実などのさまざまな応用に対応する柔軟なツールとして設計されています。映画、テレビ番組、ゲームなどのリアルな人間ビデオを作成するために使用できます。始めるには、入力画像と動きの信号をアップロードし、OmniHuman-1に残りを任せるだけです。
OmniHuman-1を使用する際の倫理的考慮は何ですか?
OmniHuman-1はリアルな人間ビデオを生成する強力なツールですが、AI生成コンテンツの倫理的影響を考慮することが重要です。OmniHuman-1によって生成されたコンテンツが適切で尊重されることを確認し、AI生成ビデオが社会や個人に与える潜在的な影響を考慮することが重要です。