OmniHuman-1
Cos'è OmniHuman-1?
OmniHuman, un innovativo framework di IA end-to-end sviluppato da ricercatori di ByteDance, rivoluziona la sintesi di video di persone generando video iperrealistici a partire da una sola immagine e un segnale di movimento come input audio o video. In grado di elaborare ritratti, riprese a mezzo busto o immagini a figura intera, offre movimenti realistici, gesti naturali e dettagli eccezionali. Nel suo nucleo, OmniHuman è un modello condizionato da multimodalità che integra senza soluzione di continuità vari input, come immagini statiche e clip audio, per creare contenuti video altamente realistici. Questo progresso, che sintetizza il movimento umano naturale a partire da dati minimi, stabilisce nuovi standard per i visual generati da IA e ha implicazioni di vasta portata per industrie come l'intrattenimento, i media e la realtà virtuale.
Panoramica di OmniHuman-1
| Caratteristica | Descrizione |
| Strumento AI | OmniHuman-1 |
| Categoria | Framework di IA Multimodale |
| Funzione | Generazione Video di Persone |
| Velocità di Generazione | Generazione video in tempo reale |
| Articolo di ricerca | arxiv.org/abs/2502.01061 |
| Sito ufficiale | omnihuman-lab.github.io |
Guida di OmniHuman-1
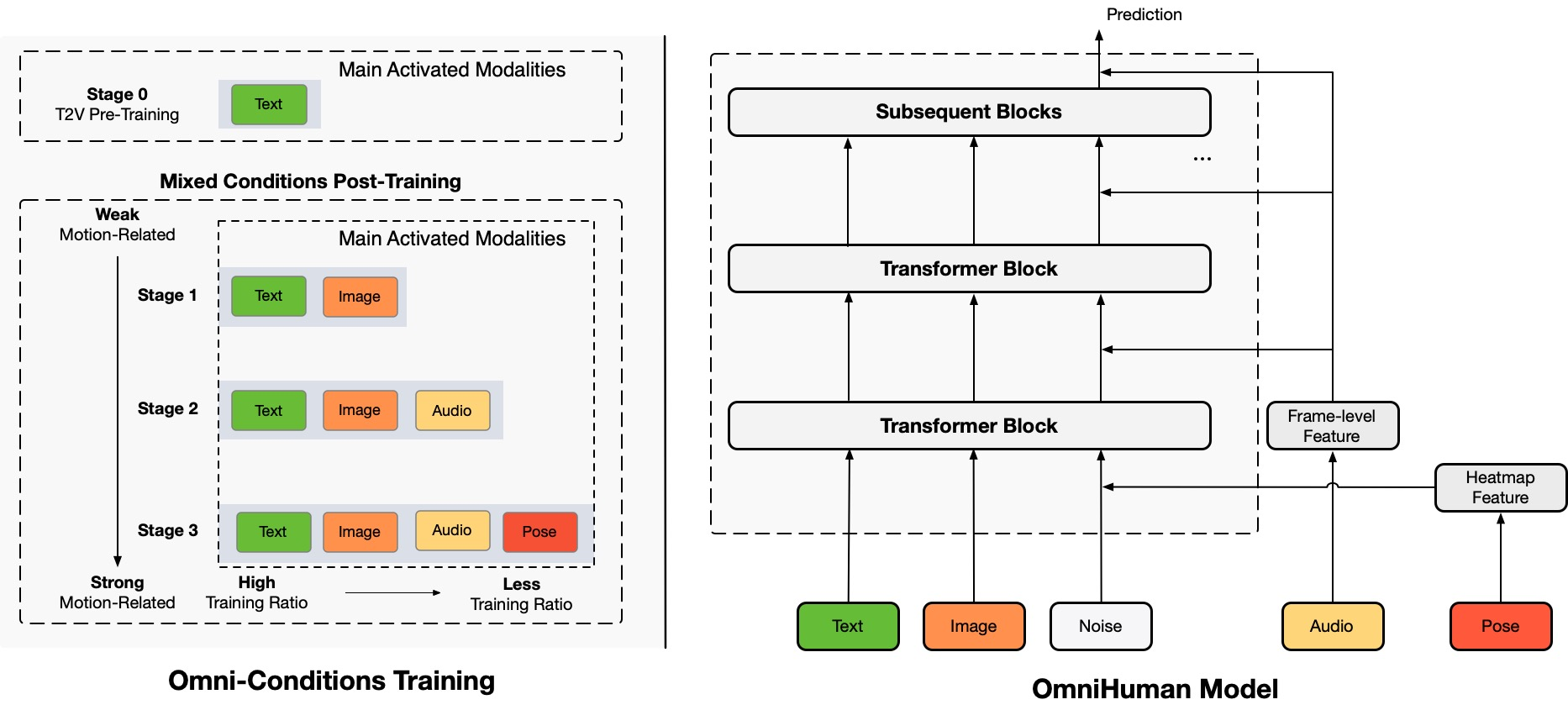
OmniHuman è un nuovo framework di generazione video di persone end-to-end condizionato da multimodalità che può produrre video di persone a partire da una singola immagine di una persona e vari segnali di movimento, come solo audio, solo video o una combinazione di entrambi. OmniHuman introduce una strategia di addestramento mista di condizionamento del movimento multimodale, che consente al modello di beneficiare della scalabilità dei dati di condizionamento misto. Questo approccio affronta efficacemente le sfide che i metodi end-to-end precedenti affrontavano a causa della disponibilità limitata di dati di alta qualità.
OmniHuman supera significativamente i metodi esistenti, specialmente nella generazione di video di persone estremamente realistici a partire da input di segnali deboli, come l'audio.
Attributi Chiave di OmniHuman-1
Generazione Video da una Singola Immagine
OmniHuman può creare video di persone estremamente realistici utilizzando solo una singola immagine di input, eliminando la necessità di dataset complessi o frame multipli.
Supporto di Input Multimodale
Il framework integra senza soluzione di continuità vari tipi di input, come immagini e clip audio, per generare contenuti video sincronizzati e realistici.
Compatibilità Versatile delle Immagini
Sia un ritratto, una ripresa a mezzo busto o un'immagine a figura intera, OmniHuman elabora tutti i tipi di immagini con precisione e realismo costanti.
Sintesi di Movimento Naturale
Il modello produce movimenti e gesti fluidi e realistici, catturando dettagli sottili che migliorano l'autenticità dei video generati.
Alta Attenzione ai Dettagli
Il framework eccelle nella rappresentazione di dettagli intricati, come espressioni facciali, linguaggio del corpo e interazioni ambientali, rendendo i video sorprendentemente realistici.
Applicazioni Scalabili
La tecnologia di OmniHuman è adattabile a vari settori, tra cui intrattenimento, realtà virtuale, gaming e produzione di media, offrendo un ampio potenziale di casi d'uso.
Innovazione Guidata dall'IA
Sfruttando algoritmi avanzati di IA, OmniHuman rappresenta un passo avanti significativo nella sintesi di video di persone, stabilendo nuovi standard di realismo e prestazioni.
Applicazioni di OmniHuman-1 nella Pratica
Cantare
OmniHuman dà vita alla musica, sia essa opera o pop. Il modello cattura le sfumature della musica e le traduce in movimenti corporei e espressioni facciali naturali. Ad esempio:
• I gesti si allineano con il ritmo e lo stile della canzone.
• Le espressioni facciali riflettono l'umore della musica.
Parlare
OmniHuman eccelle nella generazione di avatar parlanti realistici con sincronizzazione labiale precisa e gesti naturali. Le applicazioni includono:
• Influencer virtuali.
• Contenuti educativi.
Cartoni Animati e Anime
OmniHuman non è limitato solo alle persone; può animare:
• Cartoni animati.
• Animali.
Immagini di Ritratto e Mezzo Busto
OmniHuman offre risultati realistici anche in scenari di primo piano. Sia un sorriso sottile o un gesto drammatico, il modello cattura ogni dettaglio con un realismo impressionante.
Input Video
OmniHuman può imitare azioni da video di riferimento. Ad esempio:
• Usa un video di danza come segnale di movimento per generare un video di un'altra persona che esegue la stessa danza.
• Combina segnali audio e video per animare un avatar parlante che imiti sia il parlato che i gesti.
Pro e Contro di OmniHuman-1
Pro
- •Alto realismo
- •Supporto per input multimodali
- •Ampia applicabilità
- •Generazione video flessibile
- •Forte scalabilità dei dati
- •Uso efficiente di dati limitati
Contro
- •Disponibilità limitata
- •Alta domanda di risorse computazionali
- •Possibili problemi etici e tecnici
- •Limitazioni nell'effetto
- •Dipendenza dalla qualità dell'input
Come Sfruttare OmniHuman-1?
Passo 1: Input
Inizia con una singola immagine di una persona, sia una tua foto, una celebrità o anche un personaggio dei cartoni animati. Poi, aggiungi un segnale di movimento, come un clip audio di canto o parlato.
Passo 2: Elaborazione
OmniHuman utilizza una tecnica chiamata condizionamento del movimento multimodale. Questo consente al modello di interpretare e tradurre i segnali di movimento in movimenti umani realistici. Ad esempio:
• Se l'audio è una canzone, il modello genera gesti e espressioni facciali che si adattano al ritmo e allo stile della musica.
• Se è parlato, OmniHuman crea movimenti labiali e gesti sincronizzati con le parole.
Passo 3: Output
Il risultato è un video di alta qualità che dà l'impressione che la persona nell'immagine stia effettivamente cantando, parlando o eseguendo le azioni descritte dal segnale di movimento. OmniHuman produce risultati realistici anche con segnali deboli come solo input audio.
Domande Frequenti
Qual è la differenza tra OmniHuman-1 e altri modelli di generazione video di persone?
OmniHuman-1 è un framework di generazione video di persone multimodale che può generare video di persone a partire da una singola immagine di una persona e vari segnali di movimento, come solo audio, solo video o una combinazione di entrambi. Introduce una strategia di addestramento mista di condizionamento del movimento multimodale, che consente al modello di beneficiare della scalabilità dei dati di condizionamento misto. Questo approccio affronta efficacemente le sfide che i metodi end-to-end precedenti affrontavano a causa della disponibilità limitata di dati di alta qualità.
Come gestisce OmniHuman-1 diversi tipi di immagini di input?
OmniHuman-1 può gestire vari tipi di immagini di input, inclusi ritratti, riprese a mezzo busto e immagini a figura intera. Elabora tutti i tipi di immagini con precisione e realismo costanti.
Quali sono le limitazioni di OmniHuman-1?
Sebbene OmniHuman-1 eccella nella generazione di video di persone realistici, ha alcune limitazioni. Ad esempio, potrebbe avere difficoltà con scene complesse o ambienti molto dettagliati. Inoltre, il modello richiede un'immagine di riferimento di alta qualità per produrre risultati realistici. Infine, OmniHuman-1 è un modello su larga scala che richiede risorse computazionali significative.
Come posso usare OmniHuman-1 nei miei progetti?
OmniHuman-1 è progettato per essere uno strumento versatile per varie applicazioni, tra cui intrattenimento, media e realtà virtuale. Puoi usarlo per creare video di persone realistici per film, programmi TV, giochi e altro ancora. Per iniziare, carica semplicemente la tua immagine di input e il segnale di movimento, e lascia che OmniHuman-1 faccia il resto.
Quali sono le considerazioni etiche nell'uso di OmniHuman-1?
Sebbene OmniHuman-1 sia uno strumento potente per creare video di persone realistici, è importante considerare le implicazioni etiche dei contenuti generati da IA. È fondamentale assicurarsi che i contenuti generati da OmniHuman-1 siano appropriati e rispettosi, e considerare l'impatto potenziale dei video generati da IA sulla società e sugli individui.