OmniHuman-1
OmniHuman-1 क्या है?
OmniHuman बाइटडांस शोधकर्ताओं द्वारा विकसित एक नवीनतम एंड-टू-एंड एआई फ्रेमवर्क है जो केवल एक छवि और ऑडियो या वीडियो इनपुट जैसे मोशन सिग्नल से हाइपर-रियलिस्टिक वीडियो जनरेट करता है। यह पोर्ट्रेट, हाफ-बॉडी शॉट्स, या फुल-बॉडी छवियों को प्रोसेस करने में सक्षम है, और जीवंत गतियों, प्राकृतिक हावभावों और विस्तृत विवरण प्रदान करता है। अपनी कोर पर, OmniHuman एक मल्टीमॉडलिटी-कंडीशंड मॉडल है जो विविध इनपुट, जैसे स्टिल छवियां और ऑडियो क्लिप, को एकीकृत करके अत्यंत वास्तविक वीडियो सामग्री बनाता है। यह आश्चर्यजनक रूप से सीमित डेटा से प्राकृतिक मानव मोशन सिंथेसाइज़ करने की एक ब्रेकथ्रू है, जो एआई-जनरेटेड विज़ुअल्स के लिए नए मानक स्थापित करता है और मनोरंजन, मीडिया और वर्चुअल रियलिटी जैसे उद्योगों पर गहरा प्रभाव डालता है।
OmniHuman-1 का ओवरव्यू
| विशेषता | विवरण |
| एआई टूल | OmniHuman-1 |
| श्रेणी | मल्टीमॉडल एआई फ्रेमवर्क |
| फंक्शन | ह्यूमन वीडियो जनरेशन |
| जनरेशन स्पीड | रियल-टाइम वीडियो जनरेशन |
| शोध पत्र | arxiv.org/abs/2502.01061 |
| आधिकारिक वेबसाइट | omnihuman-lab.github.io |
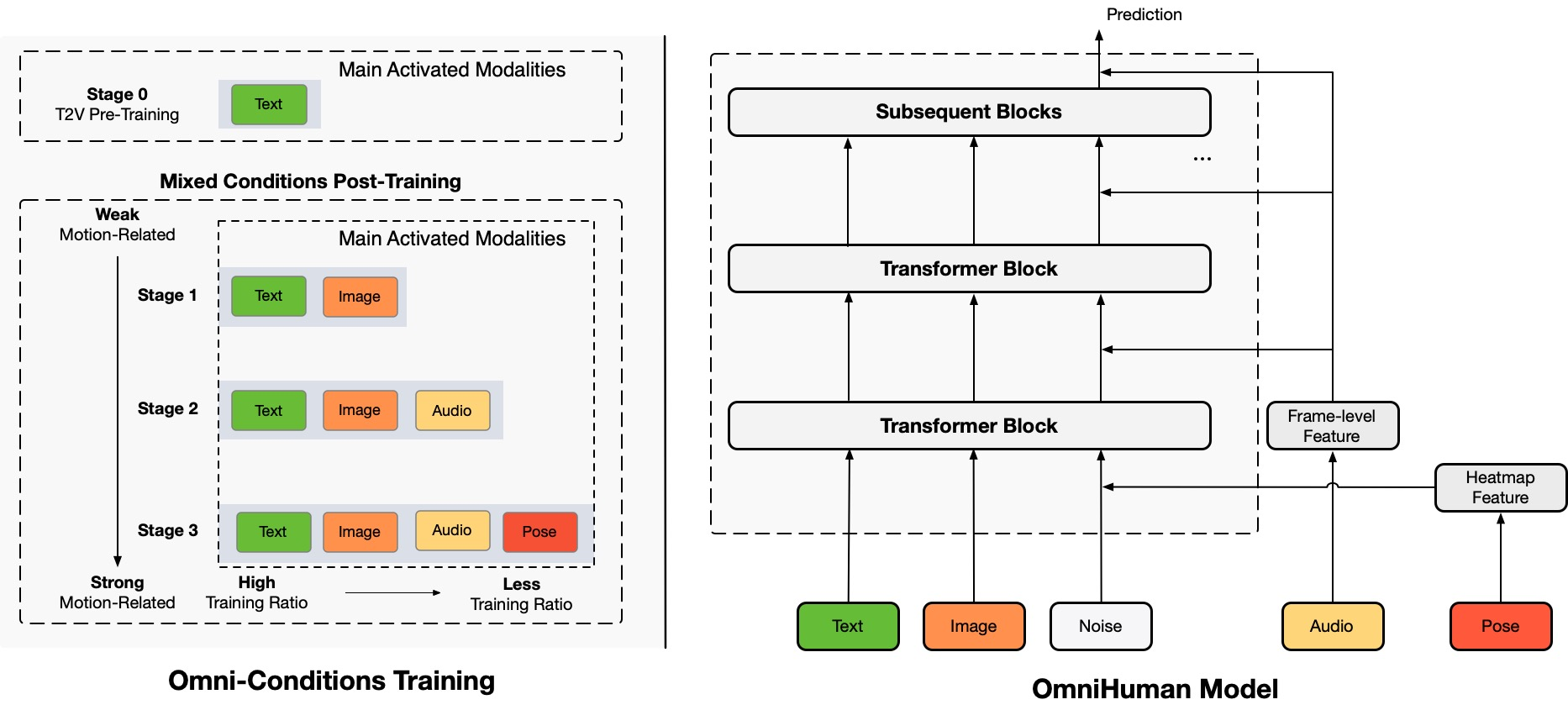
OmniHuman-1 गाइड
OmniHuman एक नवीन एंड-टू-एंड मल्टीमॉडल ह्यूमन वीडियो जनरेशन फ्रेमवर्क है जो एक एकल मानव छवि और विभिन्न मोशन सिग्नल, जैसे केवल ऑडियो, केवल वीडियो, या दोनों का संयोजन से मानव वीडियो बना सकता है। OmniHuman एक मल्टीमॉडल मोशन कंडीशनिंग मिश्रित ट्रेनिंग रणनीति पेश करता है, जो मॉडल को मिश्रित-कंडीशन डेटा की स्केलेबिलिटी से लाभ उठाने देता है। यह दृष्टिकोण पहले एंड-टू-एंड विधियों द्वारा सामना की जाने वाली समस्याओं को दूर करता है जो उच्च-गुणवत्ता वाले डेटा की सीमित उपलब्धता के कारण होती हैं।
OmniHuman मौजूदा विधियों से काफी आगे निकल गया है, विशेषकर कमजोर सिग्नल इनपुट (जैसे ऑडियो) से अत्यंत वास्तविक मानव वीडियो बनाने में।
OmniHuman-1 की प्रमुख विशेषताएं
एकल छवि से वीडियो जनरेशन
OmniHuman केवल एक इनपुट छवि का उपयोग करके अत्यंत वास्तविक मानव वीडियो बना सकता है, जिससे जटिल डेटासेट या कई फ्रेमों की आवश्यकता समाप्त हो जाती है।
मल्टीमॉडल इनपुट समर्थन
फ्रेमवर्क छवियों और ऑडियो क्लिप जैसे विभिन्न इनपुट प्रकारों को सहजता से एकीकृत करता है ताकि सिंक्रनाइज़ और जीवंत वीडियो सामग्री बनाई जा सके।
विविध छवि संगतता
चाहे यह पोर्ट्रेट, हाफ-बॉडी शॉट, या फुल-बॉडी छवि हो, OmniHuman सभी प्रकार की छवियों को समान सटीकता और वास्तविकता के साथ प्रोसेस करता है।
प्राकृतिक मोशन सिंथेसिस
मॉडल प्रवाहमान और जीवंत गतियों और हावभावों का उत्पादन करता है, जो वीडियो की प्रामाणिकता को बढ़ाने वाले सूक्ष्म विवरणों को कैप्चर करता है।
विवरणों पर उच्च ध्यान
फ्रेमवर्क जटिल विवरणों, जैसे चेहरे के भाव, शरीर की भाषा और पर्यावरणीय अंतरक्रियाओं को रेंडर करने में उत्कृष्ट है, जिससे वीडियो अत्यंत वास्तविक बन जाते हैं।
स्केलेबल एप्लिकेशंस
OmniHuman की तकनीक मनोरंजन, वर्चुअल रियलिटी, गेमिंग और मीडिया उत्पादन सहित विभिन्न उद्योगों में अनुकूलित है, जिससे व्यापक उपयोग के मामले खुलते हैं।
एआई-ड्राइवन इनोवेशन
उन्नत एआई एल्गोरिदम का उपयोग करके, OmniHuman मानव वीडियो सिंथेसिस में एक महत्वपूर्ण कदम बढ़ाता है, वास्तविकता और प्रदर्शन के लिए नए मानक स्थापित करता है।
व्यवहार में OmniHuman-1 के अनुप्रयोग
गाना
OmniHuman संगीत को जीवंत करता है, चाहे यह ओपेरा हो या पॉप। मॉडल संगीत की सूक्ष्मताओं को कैप्चर करता है और उन्हें प्राकृतिक शरीर की गतिविधियों और चेहरे के भावों में बदल देता है। उदाहरण के लिए:
• हावभाव गीत की लय और शैली के अनुरूप होते हैं।
• चेहरे के भाव संगीत के मूड को दर्शाते हैं।
बात करना
OmniHuman वास्तविक बोलने वाले अवतारों को जनरेट करने में उत्कृष्ट है, जिसमें सटीक लिप-सिंक और प्राकृतिक हावभाव होते हैं। अनुप्रयोगों में शामिल हैं:
• वर्चुअल प्रभावकारी।
• शैक्षिक सामग्री।
कार्टून और एनीमे
OmniHuman केवल मनुष्यों तक सीमित नहीं है—यह एनीमेट कर सकता है:
• कार्टून।
• जानवर।
पोर्ट्रेट और हाफ-बॉडी छवियां
OmniHuman क्लोज-अप स्थितियों में भी जीवंत परिणाम प्रदान करता है। चाहे यह एक सूक्ष्म मुस्कान हो या एक नाटकीय हावभाव, मॉडल हर विवरण को अद्भुत वास्तविकता के साथ कैप्चर करता है।
वीडियो इनपुट
OmniHuman संदर्भ वीडियो से क्रियाओं की नकल कर सकता है। उदाहरण के लिए:
• एक डांस वीडियो को मोशन सिग्नल के रूप में उपयोग करके किसी और व्यक्ति को उसी नृत्य करते हुए दिखाने वाला वीडियो बनाएं।
• ऑडियो और वीडियो सिग्नलों को मिलाकर विशिष्ट शरीर के हिस्सों को एनीमेट करें, जिससे एक बोलने वाला अवतार बने जो दोनों भाषण और हावभावों को दोहराता है।
OmniHuman-1 के फायदे और नुकसान
फायदे
- •उच्च वास्तविकता
- •मल्टीमॉडल इनपुट का समर्थन
- •व्यापक अनुप्रयोग्यता
- •लचीला वीडियो जनरेशन
- •मजबूत डेटा स्केलेबिलिटी
- •सीमित डेटा का कुशल उपयोग
नुकसान
- •सीमित उपलब्धता
- •उच्च कंप्यूटेशनल रिसोर्स डिमांड
- •संभावित नैतिक और तकनीकी मुद्दे
- •प्रभाव में सीमाएं
- •इनपुट गुणवत्ता पर निर्भरता
OmniHuman-1 कैसे उपयोग करें?
चरण 1: इनपुट
एक व्यक्ति की एक छवि से शुरू करें, चाहे वह आपकी खुद की तस्वीर हो, किसी सेलिब्रिटी की हो, या फिर कार्टून चरित्र की हो। फिर, एक मोशन सिग्नल जोड़ें, जैसे गाने या बोलने का ऑडियो क्लिप।
चरण 2: प्रोसेसिंग
OmniHuman एक तकनीक का उपयोग करता है जिसे मल्टीमॉडलिटी मोशन कंडीशनिंग कहा जाता है। यह मॉडल को मोशन सिग्नलों को वास्तविक मानव गतिविधियों में बदलने में सक्षम बनाता है। उदाहरण के लिए:
• यदि ऑडियो एक गीत है, तो मॉडल गीत की लय और शैली के अनुरूप हावभाव और चेहरे के भाव बनाता है।
• यदि यह भाषण है, तो OmniHuman शब्दों के साथ सिंक्रनाइज़ होने वाले होंठों की गतिविधियों और हावभावों को बनाता है।
चरण 3: आउटपुट
परिणाम एक उच्च-गुणवत्ता वाला वीडियो होता है जो ऐसा दिखाई देता है जैसे छवि में व्यक्ति वास्तव में गा रहा हो, बोल रहा हो, या मोशन सिग्नल द्वारा वर्णित क्रियाएं कर रहा हो। OmniHuman कमजोर सिग्नल जैसे केवल ऑडियो इनपुट के साथ भी अत्यंत वास्तविक परिणाम पैदा करने में उत्कृष्ट है।
अक्सर पूछे जाने वाले प्रश्न
OmniHuman-1 और अन्य मानव वीडियो जनरेशन मॉडल में क्या अंतर है?
OmniHuman-1 एक मल्टीमॉडल ह्यूमन वीडियो जनरेशन फ्रेमवर्क है जो एक एकल मानव छवि और विभिन्न मोशन सिग्नल, जैसे केवल ऑडियो, केवल वीडियो, या दोनों का संयोजन से मानव वीडियो बना सकता है। यह एक मल्टीमॉडल मोशन कंडीशनिंग मिश्रित ट्रेनिंग रणनीति पेश करता है, जो मॉडल को मिश्रित-कंडीशन डेटा की स्केलेबिलिटी से लाभ उठाने देता है। यह दृष्टिकोण पहले एंड-टू-एंड विधियों द्वारा सामना की जाने वाली समस्याओं को दूर करता है जो उच्च-गुणवत्ता वाले डेटा की सीमित उपलब्धता के कारण होती हैं।
OmniHuman-1 विभिन्न प्रकार की इनपुट छवियों को कैसे संभालता है?
OmniHuman-1 विभिन्न प्रकार की इनपुट छवियों को संभाल सकता है, जिसमें पोर्ट्रेट, हाफ-बॉडी शॉट्स और फुल-बॉडी छवियां शामिल हैं। यह सभी प्रकार की छवियों को समान सटीकता और वास्तविकता के साथ प्रोसेस करता है।
OmniHuman-1 की क्या सीमाएं हैं?
हालांकि OmniHuman-1 वास्तविक मानव वीडियो बनाने में उत्कृष्ट है, लेकिन इसमें कुछ सीमाएं हैं। उदाहरण के लिए, यह जटिल दृश्यों या अत्यधिक विस्तृत वातावरणों के साथ संघर्ष कर सकता है। इसके अलावा, मॉडल को वास्तविक परिणाम पैदा करने के लिए एक उच्च-गुणवत्ता वाली संदर्भ छवि की आवश्यकता होती है। अंत में, OmniHuman-1 एक बड़े पैमाने पर मॉडल है, जिसे चलाने के लिए महत्वपूर्ण कंप्यूटेशनल रिसोर्स की आवश्यकता होती है।
मैं अपने प्रोजेक्ट्स में OmniHuman-1 कैसे उपयोग कर सकता हूं?
OmniHuman-1 एक बहुमुखी टूल के रूप में डिज़ाइन किया गया है जो मनोरंजन, मीडिया और वर्चुअल रियलिटी सहित विभिन्न अनुप्रयोगों के लिए उपयोगी है। आप फिल्मों, टीवी शो, गेम्स और बहुत कुछ के लिए वास्तविक मानव वीडियो बनाने के लिए इसका उपयोग कर सकते हैं। शुरू करने के लिए, बस अपनी इनपुट छवि और मोशन सिग्नल अपलोड करें, और OmniHuman-1 बाकी का काम करेगा।
OmniHuman-1 का उपयोग करते समय नैतिक विचारों क्या हैं?
हालांकि OmniHuman-1 वास्तविक मानव वीडियो बनाने के लिए एक शक्तिशाली टूल है, लेकिन एआई-जनरेटेड सामग्री के नैतिक परिणामों को ध्यान में रखना महत्वपूर्ण है। यह सुनिश्चित करना महत्वपूर्ण है कि OmniHuman-1 द्वारा जनरेट की गई सामग्री उचित और सम्मानजनक हो, और एआई-जनरेटेड वीडियो के समाज और व्यक्तियों पर संभावित प्रभाव को ध्यान में रखा जाए।