OmniHuman-1
Qu'est-ce qu'OmniHuman-1 ?
OmniHuman, un cadre innovant d'IA de bout en bout développé par des chercheurs de ByteDance, révolutionne la synthèse de vidéos humaines en générant des vidéos hyperréalistes à partir d'une seule image et d'un signal de mouvement tel qu'une entrée audio ou vidéo. Capable de traiter des portraits, des plans de demi-corps ou des images de corps entier, il offre des mouvements réalistes, des gestes naturels et des détails exceptionnels. Au cœur d'OmniHuman se trouve un modèle conditionné par la multimodalité qui intègre parfaitement diverses entrées, telles que des images statiques et des clips audio, pour créer un contenu vidéo hautement réaliste. Cette percée, qui synthétise des mouvements humains naturels à partir de données minimales, établit de nouvelles normes pour les visuels générés par l'IA et a des implications de grande portée pour des industries comme le divertissement, les médias et la réalité virtuelle.
Aperçu d'OmniHuman-1
| Caractéristique | Description |
| Outil IA | OmniHuman-1 |
| Catégorie | Cadre IA Multimodal |
| Fonction | Génération de Vidéos Humaines |
| Vitesse de Génération | Génération de vidéo en temps réel |
| Article de recherche | arxiv.org/abs/2502.01061 |
| Site officiel | omnihuman-lab.github.io |
Guide d'OmniHuman-1
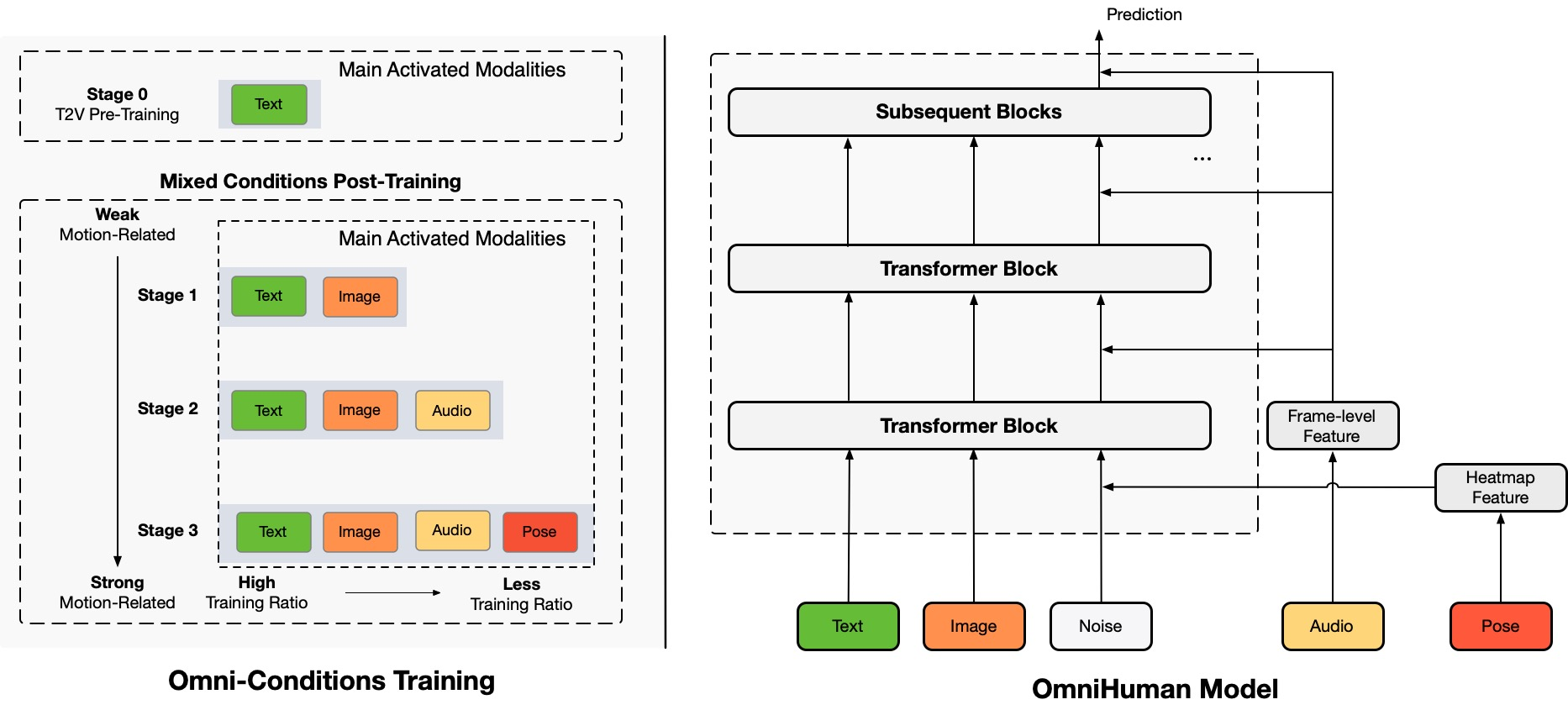
OmniHuman est un nouveau cadre de génération de vidéos humaines multimodal de bout en bout qui peut produire des vidéos humaines à partir d'une seule image humaine et de divers signaux de mouvement, tels que l'audio uniquement, la vidéo uniquement ou une combinaison des deux. OmniHuman introduit une stratégie d'entraînement mixte de conditionnement de mouvement multimodal, permettant au modèle de bénéficier de la mise à l'échelle des données de conditionnement mixte. Cette approche traite efficacement les défis auxquels étaient confrontées les méthodes de bout en bout précédentes en raison de la disponibilité limitée de données de haute qualité.
OmniHuman surpasse considérablement les méthodes existantes, en particulier dans la génération de vidéos humaines extrêmement réalistes à partir d'entrées de signaux faibles, comme l'audio.
Attributs Clés d'OmniHuman-1
Génération Vidéo à partir d'une Seule Image
OmniHuman peut créer des vidéos humaines extrêmement réalistes en utilisant une seule image d'entrée, éliminant ainsi le besoin de jeux de données complexes ou de plusieurs images.
Prise en Charge des Entrées Multimodales
Le cadre intègre parfaitement plusieurs types d'entrées, telles que des images et des clips audio, pour générer un contenu vidéo synchronisé et réaliste.
Compatibilité Versatile des Images
Qu'il s'agisse d'un portrait, d'un plan de demi-corps ou d'une image de corps entier, OmniHuman traite tous les types d'images avec une précision et un réalisme constants.
Synthèse de Mouvement Naturel
Le modèle produit des mouvements et des gestes fluides et réalistes, capturant des détails subtils qui améliorent l'authenticité des vidéos générées.
Haute Attention aux Détails
Le cadre excelle dans le rendu de détails complexes, tels que les expressions faciales, le langage corporel et les interactions environnementales, rendant les vidéos étonnamment réalistes.
Applications Évolutives
La technologie OmniHuman est adaptable à diverses industries, y compris le divertissement, la réalité virtuelle, les jeux et la production de médias, offrant un large éventail de cas d'utilisation potentiels.
Innovation Pilotée par l'IA
En exploitant des algorithmes d'IA avancés, OmniHuman représente un bond significatif dans la synthèse de vidéos humaines, établissant de nouvelles normes de réalisme et de performance.
Applications d'OmniHuman-1 dans la Pratique
Chant
OmniHuman donne vie à la musique, qu'il s'agisse d'opéra ou de pop. Le modèle capture les nuances de la musique et les traduit en mouvements corporels et expressions faciales naturels. Par exemple :
• Les gestes s'alignent avec le rythme et le style de la chanson.
• Les expressions faciales reflètent l'humeur de la musique.
Parler
OmniHuman excelle dans la génération d'avatars parlants réalistes avec une synchronisation labiale précise et des gestes naturels. Les applications incluent :
• Influenceurs virtuels.
• Contenu éducatif.
Dessins Animés et Anime
OmniHuman ne se limite pas aux humains ; il peut animer :
• Dessins animés.
• Animaux.
Images de Portrait et de Demi-Corps
OmniHuman offre également des résultats réalistes dans des scénarios de gros plan. Qu'il s'agisse d'un sourire subtil ou d'un geste dramatique, le modèle capture chaque détail avec un réalisme impressionnant.
Entrées Vidéo
OmniHuman peut imiter des actions de vidéos de référence. Par exemple :
• Utilisez une vidéo de danse comme signal de mouvement pour générer une vidéo d'une autre personne effectuant la même danse.
• Combinez des signaux audio et vidéo pour animer un avatar parlant qui imite à la fois la parole et les gestes.
Avantages et Inconvénients d'OmniHuman-1
Avantages
- •Haut réalisme
- •Prise en charge des entrées multimodales
- •Large applicabilité
- •Génération vidéo flexible
- •Forte évolutivité des données
- •Utilisation efficace des données limitées
Inconvénients
- •Disponibilité limitée
- •Forte demande en ressources informatiques
- •Problèmes éthiques et techniques potentiels
- •Limitations dans l'effet
- •Dépendance à la qualité de l'entrée
Comment Tirer Parti d'OmniHuman-1 ?
Étape 1 : Entrée
Commencez avec une seule image d'une personne, qu'il s'agisse d'une photo de vous-même, d'une célébrité ou même d'un personnage de dessin animé. Ensuite, ajoutez un signal de mouvement, tel qu'un clip audio de chant ou de parole.
Étape 2 : Traitement
OmniHuman utilise une technique appelée conditionnement de mouvement multimodal. Cela permet au modèle d'interpréter et de traduire des signaux de mouvement en mouvements humains réalistes. Par exemple :
• Si l'audio est une chanson, le modèle génère des gestes et des expressions faciales qui correspondent au rythme et au style de la musique.
• Si c'est de la parole, OmniHuman crée des mouvements labiaux et des gestes synchronisés avec les mots.
Étape 3 : Sortie
Le résultat est une vidéo de haute qualité qui donne l'impression que la personne sur l'image chante, parle ou effectue des actions décrites par le signal de mouvement. OmniHuman excelle dans la production de résultats réalistes même avec des signaux faibles comme des entrées audio uniquement.
Questions Fréquentes
Quelle est la différence entre OmniHuman-1 et d'autres modèles de génération de vidéos humaines ?
OmniHuman-1 est un cadre de génération de vidéos humaines multimodal qui peut générer des vidéos humaines à partir d'une seule image humaine et de divers signaux de mouvement, tels que l'audio uniquement, la vidéo uniquement ou une combinaison des deux. Il introduit une stratégie d'entraînement mixte de conditionnement de mouvement multimodal, permettant au modèle de bénéficier de la mise à l'échelle des données de conditionnement mixte. Cette approche traite efficacement les défis auxquels étaient confrontées les méthodes de bout en bout précédentes en raison de la disponibilité limitée de données de haute qualité.
Comment OmniHuman-1 gère-t-il différents types d'images d'entrée ?
OmniHuman-1 peut gérer divers types d'images d'entrée, y compris des portraits, des plans de demi-corps et des images de corps entier. Il traite tous les types d'images avec une précision et un réalisme constants.
Quelles sont les limitations d'OmniHuman-1 ?
Bien qu'OmniHuman-1 excelle dans la génération de vidéos humaines réalistes, il a certaines limitations. Par exemple, il pourrait avoir des difficultés avec des scènes complexes ou des environnements très détaillés. De plus, le modèle nécessite une image de référence de haute qualité pour produire des résultats réalistes. Enfin, OmniHuman-1 est un modèle à grande échelle qui nécessite des ressources informatiques significatives.
Comment puis-je utiliser OmniHuman-1 dans mes projets ?
OmniHuman-1 est conçu pour être un outil polyvalent pour diverses applications, y compris le divertissement, les médias et la réalité virtuelle. Vous pouvez l'utiliser pour créer des vidéos humaines réalistes pour des films, des émissions de télévision, des jeux et plus encore. Pour commencer, il suffit de télécharger votre image d'entrée et votre signal de mouvement, et de laisser OmniHuman-1 faire le reste.
Quelles sont les considérations éthiques lors de l'utilisation d'OmniHuman-1 ?
Bien qu'OmniHuman-1 soit un outil puissant pour créer des vidéos humaines réalistes, il est important de considérer les implications éthiques des contenus générés par l'IA. Il est crucial de s'assurer que le contenu généré par OmniHuman-1 est approprié et respectueux, et de considérer l'impact potentiel des vidéos générées par l'IA sur la société et les individus.