
The Stunning Performance of OmniHuman-1
</p> In the fields of digital humans and AI lip-sync technology, AI.TALK team, leveraging their deep industry expertise and extensive practical experience, has created approximately 300 digital humans. They have experimented with almost all open-source and proprietary digital human technologies available on the market, accumulating a wealth of hands-on experience. After participating in the beta testing of OmniHuman-1, the team has given this product exceptionally high praise,
considering it the best AI digital human product available today—bar none.
Is this an exaggeration? Let’s look at this example:

<iframe
style="width: 100%; height: auto; aspect-ratio: 16/9;" src="https://cdn.omnihuman1.org/video/0b2edmabwaaamaapygfymbtvag6ddmnqagya.f10002.mp4"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
</iframe>The strength of OmniHuman-1 lies in its ability to perfectly achieve lip-syncing for digital humans in profile views, automatically recognize lyrics in music, and enable image-based digital humans to sway naturally and interact with musical instruments.
Now, let’s take a look at the following segment:
Its mouth clarity is exceptionally high, and even under challenging conditions such as microphone obstruction or complex lighting, the lip-syncing remains accurate. Additionally, the characters can display a wide range of facial emotions in sync with the music. These capabilities left the team in awe.
Breakthroughs in Overcoming Technical Challenges
The team was established in early 2023, and along the way, they have become familiar with and tested numerous well-known products, such as D-ID and HeyGen. However, these products still face several challenges in the following technical areas:
- Facial Feature Limitations: Traditional technologies require uploading clear, unobstructed frontal photos of individuals. Photos taken from the side or at an upward angle often result in recognition failures. Even if recognition is barely achieved, the generated results are significantly compromised.
- Dynamic Limitations: In early image-based digital human technologies, body movements were stiff, with only head and mouth movements, lacking natural肢体 dynamics.
- Pixel Limitations: Conventional lip-syncing methods often lead to pixel degradation around the mouth, resulting in blurry output around the mouth, which Negatively impact the creative results.
- Rhythm Limitations: When the audio speech speed is too fast,The digital human's lip-syncing can become disordered, making it difficult to match high-frequency mouth movements.
The emergence of OmniHuman-1 has successfully overcome these technical challenges. It introduces a multimodal motion-conditioned hybrid training strategy, enabling the model to benefit from mixed-condition data expansion and addressing the scarcity of high-quality data. OmniHuman-1 supports image inputs of any aspect ratio, whether portrait, half-body, or full-body images, delivering vivid and high-quality results across various scenarios.
The Innovative Value of OmniHuman-1
It eliminates angle restrictions. When we upload images to create digital humans, platforms generally require users to submit clear, unobstructed frontal photos of individuals. The reason is simple: the core of this technology relies on Accurately recognize facial features. If it fails, prompts like "Unable to recognize face" will appear. Therefore, photos like the ones below are definitely unacceptable, as side or upward angles often lead to recognition failures. Sometimes, with luck, a 45-degree side angle might be recognized, but the generated results will be significantly compromised, with issues like distorted mouths being common.


Now, let’s take a look at OmniHuman-1’s performance with 90-degree side profiles and upward angles:
The lip-syncing in both videos is almost perfect, accompanied by a wide range of natural movements. Note that this isn’t a difference between strong and weak performance—it’s a difference between what’s possible and what’s impossible.
OmniHuman-1 eliminates angle restrictions, allowing characters in film and video production to "unlock" a wide range of dialogue angles and shot compositions, no longer limited to facing the camera directly. Additionally, the improved facial feature recognition also enhances tolerance for non-human faces, such as animals. For example, a 3D-style lamb can now achieve basic lip-syncing and dialogue recognition, meeting the needs of daily creation.
Moreover, the increased tolerance for facial features is also reflected in the recognition of different styles, such as the 2D anime and ink-wash styles mentioned below. While other models can also generate lip movements in these styles, in terms of completeness and the dynamics of body movements, OmniHuman-1 is still the best at present. This leads to the next issue regarding image-based digital humans.
OmniHuman-1 excels in dynamic visual performance at the I2V (Image-to-Video) level. Take the example of Sun Wukong (the Monkey King): His facial recognition is highly accurate, and when he speaks, his entire body and the surrounding environment are in a natural, high-amplitude motion. The up-and-down movement of his head seamlessly integrates with the rhythm of his body, and even the water waves synchronize with his actions, as if driving an animated video generation from a single image.
In terms of music, OmniHuman-1 has undergone targeted optimization. In addition to directly recognizing lyrics in music, the characters' faces can also display a wide range of emotions and support multi-person singing and instrument performances.
Its lip pixel performance is even more astonishing. It not only retains the original facial features of the character but also achieves an incredibly high level of clarity. For example, in the close-up details of Fok's animation and a female singer, even the generated teeth are extremely naturally reproduced.
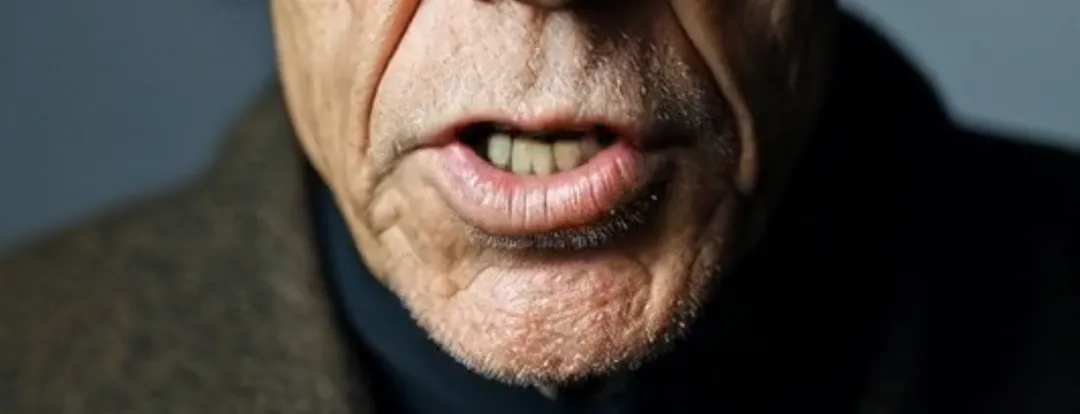
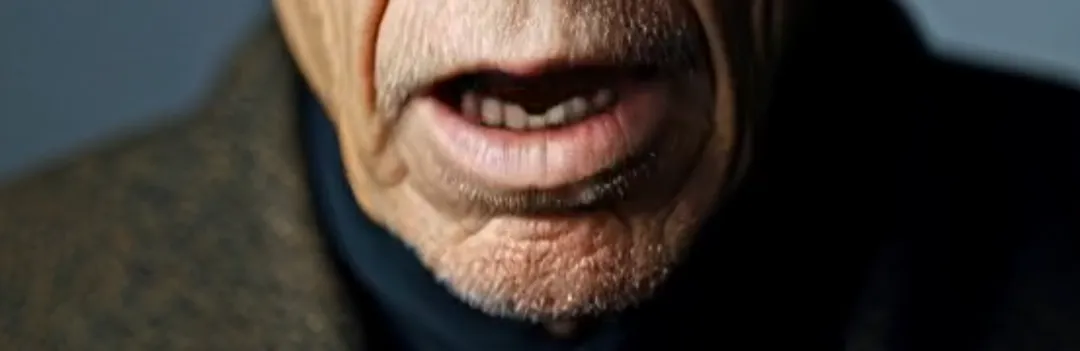



Next is the pixel recognition, which involves two elements that often interfere with lip-syncing: strong lighting and long beards. The former can cause images with intense light and shadow contrasts to fail in video generation. In Runway, it would prompt “excessive light and shadow contrast.” For example, in a sample video, an elderly person sitting in a car has constantly changing shadows on their face. Besides OmniHuman-1, almost no other platform can successfully replace the lips. Long beards, on the other hand, often cause blurriness around the mouth. However, as seen in the sample clips, OmniHuman-1 can almost perfectly reproduce the beards without any loss of detail.
Impressive, there are no other words to describe it.
The final challenge is the problem of speaking too quickly. Anyone with experience has encountered this: when the speech rate in the audio you provide is too fast, the digital human's lip-syncing will definitely become disordered. This is because the animation frame rate struggles to match the high-frequency changes in lip movements, resulting in a mismatch. However, OmniHuman-1 has also addressed this issue very well. In the segment with Steve Jobs speaking at an extremely fast pace, there are almost no flaws in the lip-syncing. Even for rap music, it should not be a problem.
Existing Issues and Future Outlook
Despite its significant technological advancements, OmniHuman-1 still has areas for improvement. Currently, OmniHuman-1 does not offer any fine-tuning functions. For example, when characters speak, the amplitude of their movements can be too large. It is suggested that options for fine-tuning the amplitude of body movements and providing more choices for limb actions should be added. Moreover, OmniHuman-1 currently only supports image-driven animations and does not yet support video lip-syncing. It is hoped that this feature will be introduced soon. The current limitation of 15 seconds for generated content is not short, but there is still room for improvement. In terms of generation speed, during the internal testing phase, it takes approximately 15-20 minutes to generate a single clip. It is hoped that this process can be optimized and made more efficient when the product is officially launched.
Summary
With its strong technical capabilities and outstanding performance, OmniHuman-1 is undoubtedly the best AI digital human product currently available. It has achieved top-level performance in facial feature tolerance, precision, and aesthetic appeal, with clear advantages in individual functions. Its launch is expected to significantly boost the application of digital humans and AI music videos and bring more possibilities to film and television production. OmniHuman-1 has delivered a game-changing impact on the AI digital human field, and we look forward to more surprises when it is officially launched.
This article is adapted from the content by blogger Han Qing from AITalk, with special thanks.